Нейросети обработки фото и изображений — это одна из самых популярных областей искусственного интеллекта. Они могут использоваться для решения различных задач, таких как улучшение качества изображений, создание новых изображений, перенос стиля между изображениями и т.д.
В этой статье мы рассмотрим 10 лучших нейросетей для обработки изображений и приведем примеры их работ.
Нейросеть DeepDream
DeepDream — это нейросеть, разработанная Google, которая может создавать гипнотические изображения, используя сверточные нейронные сети. Сеть может находить скрытые объекты в изображениях и повышать их контрастность, что создает эффектный визуальный эффект.
Эта технология была разработана в Google в 2015 году и получила широкое признание среди художников и фотографов.
Кто и когда разработал DeepDream
Нейросеть DeepDream была разработана командой исследователей из Google в 2015 году. В ее создании принимали участие Алекс Кравец, Гален Андрю, Майкл Тайсон и другие специалисты. На тот момент, DeepDream представляла собой экспериментальный проект, который позволял исследовать возможности нейросетей глубокого обучения.
Как работает DeepDream
Нейросеть DeepDream работает по принципу переобучения. Она принимает на вход изображение и обрабатывает его с помощью нейронов, которые обучены распознавать различные объекты на изображении. В результате обработки, DeepDream создает новое изображение, которое визуально похоже на исходное, но содержит дополнительные элементы и детали.
Условия использования
DeepDream может использоваться для создания художественных работ или для обработки фотографий. Однако, для использования этой нейросети необходимы навыки работы с программами глубокого обучения и понимание ее особенностей. Кроме того, необходимо иметь достаточно мощный компьютер, способный обрабатывать большие объемы данных.
Процесс генерации изображений
Процесс генерации изображений с помощью DeepDream начинается с выбора исходного изображения. Затем, нейросеть обрабатывает его, используя различные наборы фильтров и параметров. В процессе обработки, DeepDream создает новые элементы на изображении, которые напоминают формы и цвета, которые присутствовали в нейронных сетях обучения.
Как правило, процесс генерации изображений с помощью DeepDream основывается на итерационном алгоритме, который позволяет улучшать качество изображения с каждой новой обработкой. Чем больше итераций, тем более сложными становятся детали на изображении.
Примеры работ:











Нейросеть StyleGAN
StyleGAN — это нейросеть, разработанная NVIDIA, которая может генерировать уникальные реалистичные изображения. Она может изменять различные атрибуты изображения, такие как цвет, форма и стиль, чтобы создать новое, уникальное изображение.
Этот инструмент, который позволяет генерировать изображения с высоким разрешением, используя нейросети глубокого обучения. Технология была разработана в NVIDIA в 2018 году и получила широкое признание в сфере искусства и дизайна.
Кто и когда разработал StyleGAN
Нейросеть StyleGAN была разработана командой исследователей из NVIDIA в 2018 году. В ее создании принимали участие Теро Карраскорпи, Сэмпат Ичеполи, Эмильян Стеклов и другие специалисты. На тот момент, StyleGAN представляла собой новаторский подход к генерации изображений, который использовал генеративно-состязательные сети (GAN) и стилизующие модули.
Как работает StyleGAN
Нейросеть StyleGAN работает на основе GAN-архитектуры, которая состоит из двух нейросетей: генератора и дискриминатора. Генератор создает новые изображения, которые похожи на исходные, а дискриминатор определяет, насколько эти изображения похожи на настоящие.
Особенностью StyleGAN является возможность изменять стиль, цветовую гамму и форму объектов на изображении, что позволяет создавать уникальные художественные работы. Также, StyleGAN позволяет генерировать изображения с высоким разрешением, что отличает ее от других нейросетей глубокого обучения.
Условия использования
Для использования нейросети StyleGAN необходимы навыки работы с программами глубокого обучения и понимание ее особенностей. Кроме того, для создания изображений с высоким разрешением необходимо иметь мощный компьютер с высокой производительностью.
Процесс генерации изображений
Процесс генерации изображений с помощью StyleGAN начинается с выбора набора данных, на основе которого будет создаваться изображение. Затем, нейросеть генерирует изображения, используя обученную модель и стилизующие модули.
В процессе генерации изображения, StyleGAN применяет различные методы для изменения стиля и формы объектов на изображении. Эти методы включают в себя изменение параметров, таких как яркость, насыщенность, размерность и цветовую гамму. Также, нейросеть может использовать статистические методы для создания изображений, которые будут похожи на реальные фотографии.
Важным аспектом генерации изображений с помощью StyleGAN является контроль качества. Чтобы получить наилучший результат, необходимо настроить параметры нейросети и обучить ее на большом количестве данных. Кроме того, генерация изображений с высоким разрешением может занять много времени и требует высокой вычислительной мощности.
Примеры работ:










Нейросеть CycleGAN
Нейросеть CycleGAN – это инструмент, который позволяет преобразовывать изображения из одного стиля в другой. Разработана она была в 2017 году командой исследователей из Университета Беркли в Калифорнии. CycleGAN используется в различных областях, например, в дизайне, визуальных эффектах, а также в медицинских исследованиях.
Как работает CycleGAN?
CycleGAN основывается на концепции условного генеративно-состязательной нейронной сети (conditional GAN). Эта модель позволяет преобразовывать изображения из одного стиля в другой, используя две генеративные нейронные сети и две дискриминативные нейронные сети.
Первая генеративная нейронная сеть преобразует изображения из стиля А в стиль В, а вторая – наоборот. Дискриминативные нейронные сети определяют, насколько хорошо генерируемое изображение соответствует оригинальному изображению.
CycleGAN работает в двух направлениях, что позволяет сохранить информацию об изображении при преобразовании из одного стиля в другой. В результате получаются изображения, которые выглядят так, будто они были созданы в исходном стиле, но при этом содержат элементы из другого стиля.
Процесс генерации изображений с помощью CycleGAN
Процесс генерации изображений с помощью CycleGAN состоит из нескольких этапов. Вначале необходимо собрать набор данных изображений в обоих стилях. Затем, данные разбиваются на обучающую и тестовую выборки.
После этого, происходит обучение генеративных и дискриминативных нейронных сетей на обучающей выборке. В процессе обучения нейронные сети уточняют свои параметры, чтобы сгенерировать наиболее качественные изображения.
После обучения CycleGAN можно использовать для преобразования изображений из одного стиля в другой. Для этого необходимо загрузить исходное изображение в CycleGAN, выбрать желаемый стиль и запустить процесс преобразования. CycleGAN сгенерирует новое изображение в выбранном стиле.
Условия использования CycleGAN
CycleGAN является открытым исходным кодом и может использоваться бесплатно. Однако, перед использованием этого инструмента, необходимо убедиться в том, что вы соответствуете требованиям лицензии и уведомлений об авторском праве.
CycleGAN подходит для использования в различных областях, включая дизайн, визуальные эффекты, медицинские исследования, а также в других областях, где требуется преобразование изображений из одного стиля в другой.
Применение CycleGAN
CycleGAN может использоваться в различных областях. Например, в дизайне можно использовать эту нейросеть для преобразования изображений в различных стилях, чтобы создавать оригинальные дизайнерские решения.
Визуальные эффекты – еще одна область применения CycleGAN. Например, с помощью этой нейросети можно создавать качественные визуальные эффекты для фильмов и телевизионных передач.
Медицинские исследования – это еще одна область, где может быть использована CycleGAN. С помощью этой нейросети можно преобразовывать медицинские изображения, чтобы увеличить точность диагностики и облегчить работу врачей.
Примеры работ:



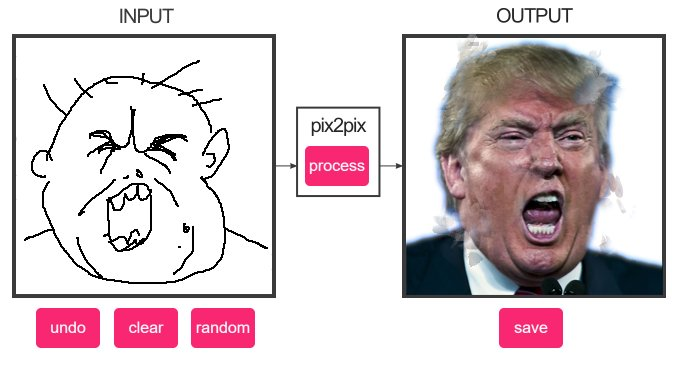
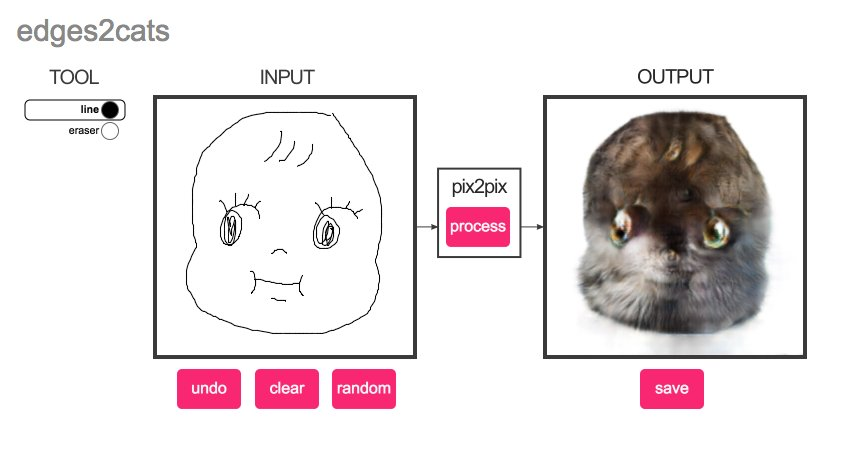
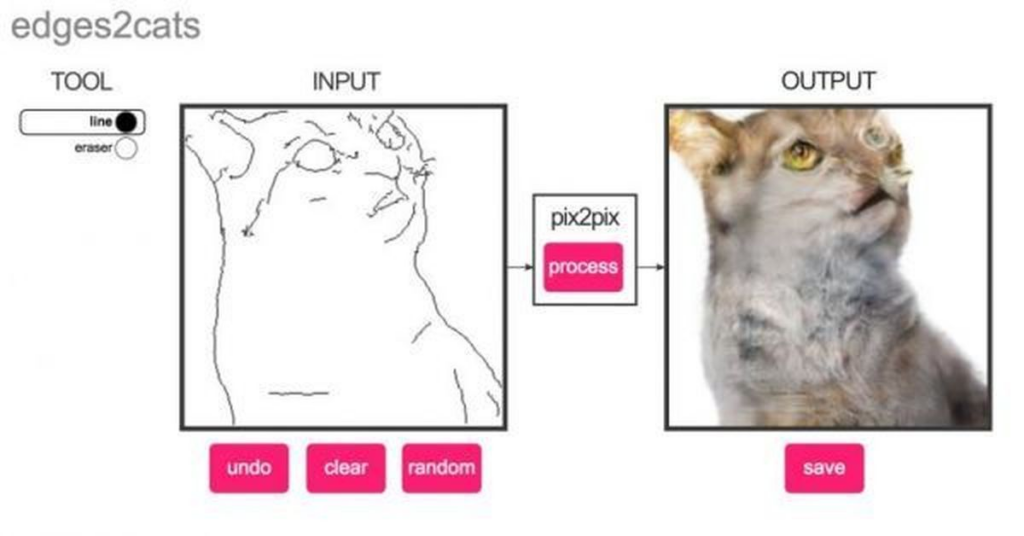
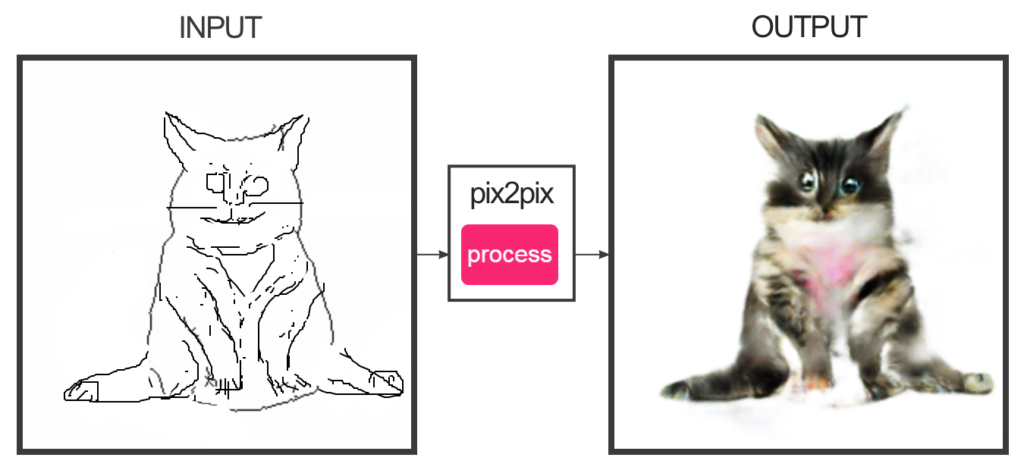
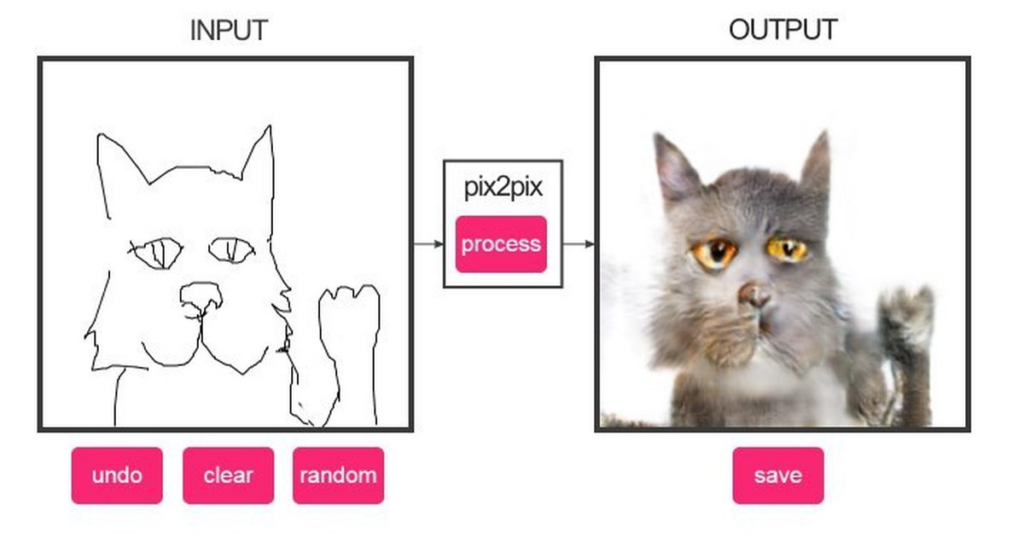
Нейросеть Pix2Pix
Pix2Pix — это нейросеть, которая может создавать новые изображения из существующих. Она может использоваться для создания фотореалистичных изображений на основе рисунков или даже для удаления объектов с изображений.
Нейросеть Pix2Pix была разработана в 2016 году командой ученых из Университета Беркли и Adobe Research. Она является частью семейства GAN-моделей и используется для решения задачи преобразования одного изображения в другое. Нейросеть Pix2Pix является одной из самых популярных и широко используемых нейросетей для создания реалистичных изображений.
Как работает нейросеть Pix2Pix?
Нейросеть Pix2Pix работает на основе условных генеративных состязательных сетей (cGAN), где обучение происходит на основе пар изображений: одно является входным, а другое — целевым. Pix2Pix обучается на множестве пар изображений и учится связывать эти изображения друг с другом, чтобы создавать реалистичные изображения, используя информацию из входного изображения.
Например, нейросеть может использоваться для преобразования черно-белых изображений в цветные. Входное черно-белое изображение подается на вход нейросети, а выходное цветное изображение – это цель, которую необходимо достичь. Нейросеть обучается сопоставлять входное изображение с соответствующим цветным изображением. Как только обучение завершено, нейросеть может использоваться для создания новых цветных изображений на основе входных черно-белых.
Условия использования нейросети Pix2Pix
Нейросеть Pix2Pix доступна для использования в общественном доступе и может быть использована бесплатно. Однако, для использования этой нейросети необходимы знания в области машинного обучения и программирования. Кроме того, необходимо соблюдать условия лицензии и уведомлений об авторском праве.
Применение нейросети Pix2Pix
Нейросеть Pix2Pix может использоваться в различных областях, включая графический дизайн, медицину, архитектуру, робототехнику и другие области. Например, в графическом дизайне Pix2Pix может использоваться для создания цветных изображений на основе черно-белых или для преобразования одного стиля в другой.
Процесс генерации изображений с использованием нейросети Pix2Pix основан на подаче пары изображений на вход нейросети. Одно изображение из пары является входным, а другое – выходным, которое необходимо сгенерировать. Нейросеть обучается на большом количестве пар изображений, чтобы научиться генерировать правильные выходные изображения.
Для обучения нейросети используется функция потерь, которая измеряет разницу между сгенерированным и оригинальным выходным изображением. Чем меньше разница между этими изображениями, тем выше качество работы нейросети.
Одна из главных особенностей нейросети Pix2Pix заключается в том, что она может генерировать выходные изображения разных размеров и разных типов. Также возможна генерация изображений в нескольких цветовых пространствах.
Применение нейросети Pix2Pix находит широкое применение в области компьютерного зрения, в том числе в задачах переноса стиля, сегментации изображений, преобразования картинок и других задач.
Примеры работ:


Нейросеть SRGAN
Нейросеть SRGAN – это глубокая нейросеть, разработанная в 2017 году исследователями из университета Техаса Алексом Жеттом и Виваком Агравалом. Она используется для генерации высококачественных изображений с повышенным разрешением (Super-Resolution), что делает ее особенно полезной в области компьютерного зрения.
Как работает нейросеть SRGAN?
SRGAN использует нейросети глубокого обучения, чтобы увеличить разрешение низкокачественных изображений до более высокого. Это достигается путем обучения нейросети на большом количестве низкокачественных изображений и соответствующих им высококачественных изображений.
Для того, чтобы получить высококачественное изображение, SRGAN использует генератор и дискриминатор. Генератор отвечает за создание изображения с повышенным разрешением, а дискриминатор – за оценку качества изображения, чтобы генератор мог научиться создавать более качественные изображения.
Условия использования нейросети SRGAN
Одна из ключевых особенностей нейросети SRGAN заключается в использовании метода восстановления контента (Content Reconstruction). Этот метод позволяет сохранить информацию о контенте (содержимом) изображения, даже при увеличении его разрешения. Благодаря этому методу, изображения, сгенерированные нейросетью SRGAN, сохраняют оригинальный контент и выглядят более естественно и качественно.
Применение нейросети SRGAN
Применение нейросети SRGAN может быть полезно во многих областях, включая компьютерное зрение, медицину, робототехнику, а также в индустрии развлечений и игр.
Однако, для эффективного использования нейросети SRGAN необходимо иметь большой объем обучающих данных, чтобы достичь высокой точности и качества изображений.
Примеры работ:










Нейросеть U-Net
Нейросети являются мощным инструментом в области обработки изображений. Они могут использоваться для решения различных задач, таких как классификация изображений, сегментация изображений и восстановление изображений. В данной статье мы поговорим об одной из наиболее популярных нейросетей для сегментации изображений — U-Net.
История создания
Нейросеть U-Net была разработана в 2015 году Олеем Цой и Томасом Броссом во Фрайбургском университете в Германии. Их целью было создание нейросети для сегментации медицинских изображений, которая могла бы эффективно и точно выделять различные структуры на изображении. В качестве примера они использовали задачу сегментации клеток на изображениях микроскопа.
Как работает нейросеть U-Net?
Нейросеть U-Net имеет архитектуру, которая состоит из энкодера и декодера. Энкодер содержит сверточные слои, которые используются для извлечения признаков из изображения. Декодер также содержит сверточные слои, которые используются для восстановления изображения.
Одной из особенностей нейросети U-Net является наличие пути объединения, который соединяет сверточные слои из энкодера с соответствующими слоями из декодера. Это позволяет увеличить точность сегментации, так как информация, полученная на разных уровнях абстракции, используется для определения границ объектов на изображении.
Нейросеть U-Net использует функцию потерь, которая оценивает разницу между выходом сети и правильным ответом. Для обучения сети используется метод обратного распространения ошибки.
Примеры использования
Нейросеть U-Net широко используется для сегментации медицинских изображений, таких как изображения мозга, легких и сетчатки. Также она может применяться для сегментации других типов изображений, например, для сегментации дорожной разметки на фотографиях.
Одним из примеров использования нейросети U-Net является проект SegNet.
Процесс генерации изображений с использованием U-Net
Генерация изображений с использованием U-Net может быть выполнена в несколько этапов:
- Подготовка данных: Для обучения модели необходимо иметь набор данных, состоящий из изображений и соответствующих им масок. Маски представляют из себя изображения, где белый цвет обозначает область интереса, а черный — фон. Набор данных может быть получен путем разметки изображений вручную или с использованием автоматических инструментов разметки данных.
- Обучение модели: Для обучения модели необходимо использовать набор данных, подготовленный на предыдущем этапе. Обучение производится путем передачи изображения через нейросеть и сравнения полученного изображения с маской, чтобы определить, насколько хорошо модель предсказывает маску. Обучение может занять несколько дней или недель, в зависимости от объема данных и параметров модели.
- Тестирование модели: После того, как модель была обучена на наборе данных, можно приступить к ее тестированию. Для этого модель подается на изображение, и она должна сгенерировать маску, которая наилучшим образом соответствует изображению. После этого можно оценить качество работы модели с помощью различных метрик, таких как точность, полнота и F-мера.
- Применение модели: После успешного тестирования модель можно использовать для генерации изображений на новых данных. Для этого необходимо просто подать новое изображение через нейросеть, и она сгенерирует соответствующую маску и изображение.
Примеры работ:







Нейросеть Mask R-CNN
Mask R-CNN — это нейросеть, которая может использоваться для обнаружения объектов на изображениях и разметки их границ. Она может быть полезна для автоматического анализа изображений, таких как фотографии природы или медицинские изображения.
История создания
Нейросеть Mask R-CNN была разработана в 2017 году командой Facebook AI Research. Эта нейросеть является улучшенной версией Faster R-CNN, которая также была разработана в Facebook AI Research в 2015 году. Faster R-CNN позволяет обнаруживать объекты на изображении, но не предоставляет сегментацию объектов. Mask R-CNN была создана для того, чтобы решить эту проблему и добавить возможность сегментации объектов.
Принцип работы
Mask R-CNN является нейросетью, которая сочетает в себе Faster R-CNN и нейросеть FCN (Fully Convolutional Network) для сегментации объектов. Она использует сверточную нейросеть для обнаружения объектов и одновременно генерирует маски сегментации для каждого обнаруженного объекта. Для каждого объекта сначала определяется его местоположение на изображении, затем генерируется маска сегментации, которая указывает, какие пиксели на изображении принадлежат данному объекту.
Процесс работы Mask R-CNN состоит из нескольких этапов:
- Обнаружение объектов (Object Detection) — с помощью сверточной нейронной сети обнаруживаются объекты на изображении. Каждый объект описывается координатами (x, y) и шириной/высотой (w, h).
- Генерация масок (Mask Generation) — для каждого обнаруженного объекта генерируется бинарная маска, которая показывает, где на изображении находится объект и где его нет. Для этого используется отдельная нейронная сеть, которая обучается генерировать маски на основе обнаруженных объектов.
- Классификация объектов (Object Classification) — каждый обнаруженный объект классифицируется на определенный класс. Например, на изображении могут быть обнаружены люди, машины, деревья и т.д.
- Постобработка (Post-processing) — результаты обработки объединяются и уточняются с помощью различных алгоритмов постобработки. Например, могут быть удалены дублирующиеся объекты, объекты могут быть уточнены в размере и т.д.
Использование Mask R-CNN
Mask R-CNN может быть использована в различных задачах компьютерного зрения, в которых необходимо обнаружение объектов, генерация масок и классификация объектов на изображениях. Например, это может быть задача автоматической сегментации медицинских изображений, задача распознавания лиц или задача обработки изображений в робототехнике.
Одним из примеров применения Mask R-CNN является задача сегментации городской среды на изображениях с камер наблюдения. В этой задаче необходимо обнаруживать объекты на изображении (машины, люди, здания и т.д.), генерировать для каждого объекта маску и классифицировать объекты на определенные классы. Результаты такой обработки могут быть использованы для анализа трафика, управления светофорами и т.д.
Примеры работ:



Нейросеть Neural Style Transfer
Neural Style Transfer — это нейросеть, которая может переносить стиль одного изображения на другое. Она может быть использована для создания новых художественных работ или для создания уникальных фотографий с различными стилями.
Разработка нейросети Neural Style Transfer
Нейросеть Neural Style Transfer была разработана Леоном Гатисом, Алексом Эккертом и Маттиасом Бетге в 2015 году. Они опубликовали статью «A Neural Algorithm of Artistic Style», в которой описывали, как они смогли создать алгоритм, который может преобразовывать изображения в соответствии со стилем других изображений.
Принцип работы нейросети Neural Style Transfer
Нейросеть Neural Style Transfer использует две нейронные сети, которые работают вместе: сеть генерации контента и сеть генерации стиля. Сначала изображение, которое нужно изменить, загружается в сеть генерации контента. Затем выбирается изображение, стиль которого нужно применить к данному изображению, и загружается в сеть генерации стиля.
Сеть генерации контента и сеть генерации стиля работают параллельно, пока не будет достигнут результат, который удовлетворит заданные параметры. Сеть генерации контента используется для сохранения основной структуры изображения, в то время как сеть генерации стиля используется для изменения текстуры и цветовых оттенков изображения.
Условия использования нейросети Neural Style Transfer
Нейросеть Neural Style Transfer является открытым исходным кодом, что означает, что ее можно использовать в коммерческих и некоммерческих целях без ограничений. Однако, для использования этой нейросети нужно иметь знания в области машинного обучения и программирования.
Процесс генерации изображений
Процесс генерации изображений с использованием нейросети Neural Style Transfer может занять от нескольких минут до нескольких часов, в зависимости от размера и сложности изображения.
Помимо этого, Neural Style Transfer имеет ряд ограничений и недостатков. Одним из них является высокое время обучения и вычислений, что требует мощного аппаратного обеспечения. Также некоторые изображения могут не давать хороший результат при применении определенного стиля, что требует экспериментов и настройки параметров.
Несмотря на эти недостатки, Neural Style Transfer является мощным инструментом для создания уникальных и красивых изображений, объединяющих в себе характеристики различных стилей и контента. Это привлекает внимание искусствоведов, дизайнеров, архитекторов и других творческих профессий.
Примеры работ:









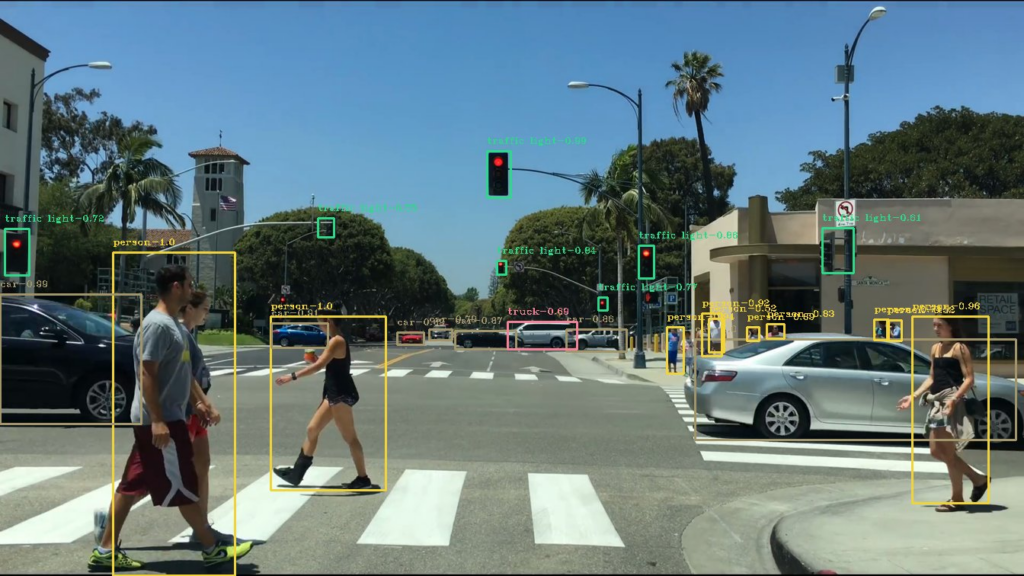
Нейросеть YOLOv5
YOLOv5 — это одна из самых популярных нейросетей, используемых для обнаружения объектов в реальном времени. Эта нейросеть была разработана компанией Ultralytics в 2020 году и получила широкое распространение благодаря своей высокой скорости и точности.
История создания
Идея создания YOLOv5 пришла после успеха предыдущей версии YOLOv4, которая была разработана в 2020 году командой разработчиков из компании Darknet. Компания Ultralytics решила продолжить работу над разработкой этой нейросети, улучшив ее архитектуру и скорость работы.
Принцип работы
YOLOv5 — это нейросеть, основанная на архитектуре EfficientDet и ориентированная на задачи обнаружения объектов в реальном времени. Она использует алгоритмы машинного обучения для обработки изображений и выделения на них объектов.
Нейросеть состоит из нескольких слоев, каждый из которых отвечает за определенную задачу. Входные данные подаются на первый слой, где происходит их обработка. Далее информация передается на следующие слои, где происходит выделение объектов на изображении. Каждый объект определяется координатами его границ и классом, к которому он относится.
Условия использования
YOLOv5 может быть использована в любой области, где требуется обнаружение объектов на изображениях. Однако, для использования нейросети необходимо иметь определенные знания в области машинного обучения и опыт работы с нейросетями.
Процесс генерации изображений
Процесс генерации изображений с помощью YOLOv5 заключается в следующем:
- Подготовка данных. Нейросеть требует наличия большого количества данных для обучения, которые должны быть размечены и подготовлены в определенном формате.
- Обучение нейросети. Данные, подготовленные на первом этапе, используются для обучения нейросети. Обучение заключается в настройке параметров нейросети, чтобы она могла определять объекты на изображении.
Примеры работ:

Нейросеть Fast R-CNN
Fast R-CNN — это нейросеть для обнаружения объектов, основанная на сверточных нейронных сетях (CNN). Она была разработана в 2015 году Россом Гирушейни и командой исследователей из Microsoft Research. На момент своего создания Fast R-CNN установила новый стандарт в области обнаружения объектов на изображениях.
Принцип работы
Fast R-CNN является модификацией своего предшественника, R-CNN (Region-based Convolutional Neural Network). Как и в R-CNN, Fast R-CNN использует двухэтапный подход для обнаружения объектов. Однако в Fast R-CNN были внесены значительные улучшения, что привело к увеличению скорости работы модели.
Первый этап заключается в выделении областей, где могут находиться объекты, на изображении. Для этого используется алгоритм selective search, который генерирует набор предложений областей, где могут быть объекты. Затем каждая область подвергается ресайзу и нормализации и подается на вход сверточной нейронной сети.
Второй этап заключается в классификации объектов внутри каждой области. Для этого используется глубокая сверточная нейронная сеть, которая обучается на задаче классификации объектов. На выходе нейросеть выдает вероятность присутствия объекта в каждой области.
Далее, с использованием прогнозов классификации, Fast R-CNN вычисляет координаты прямоугольной области, охватывающей каждый объект. Эти координаты затем используются для выделения объектов на изображении.
Условия использования
Fast R-CNN доступна для использования в качестве открытого исходного кода под лицензией MIT. Это означает, что вы можете свободно использовать, модифицировать и распространять код. Однако, как и большинство нейросетей для обнаружения объектов, Fast R-CNN требует больших объемов данных для обучения и вычислительной мощности для работы. Кроме того, для достижения наилучших результатов, Fast R-CNN должна быть обучена на наборе данных, который соответствует вашей конкретной задаче.
Процесс генерации изображений
- Препроцессинг изображения — перед тем, как передать изображение в нейронную сеть, необходимо выполнить ряд преобразований. В частности, изображение должно быть масштабировано до фиксированного размера и приведено к определенному формату. Этот процесс называется препроцессингом.
- Передача изображения через сверточную нейронную сеть — Fast R-CNN использует сверточную нейронную сеть для извлечения признаков из входного изображения. Входное изображение проходит через несколько сверточных слоев, каждый из которых обрабатывает изображение и извлекает более высокоуровневые признаки, такие как границы объектов.
- Поиск предложений — после того, как признаки извлечены из изображения, Fast R-CNN ищет предложения, которые могут содержать объекты. Для этого используется Region Proposal Network (RPN), который на основе признаков, полученных из сверточных слоев, генерирует несколько прямоугольных областей, в которых могут находиться объекты.
- Извлечение признаков из предложений — для каждого найденного предложения извлекаются признаки, используя тот же сверточный слой, который использовался для извлечения признаков из всего изображения. Таким образом, для каждого предложения генерируется вектор признаков, который описывает содержимое предложения.
- Классификация и регрессия — следующим шагом является классификация и регрессия для каждого предложения. Классификация выполняется с помощью полносвязных слоев, которые определяют, какой класс соответствует каждому предложению. Регрессия определяет координаты ограничивающего прямоугольника для каждого предложения.
- Не максимальное подавление — последний шаг включает применение алгоритма не максимального подавления (NMS), который удаляет предложения, которые сильно перекрываются с другими предложениями с более высокими оценками доверия. Это позволяет оставить только наиболее точные предложения.
Примеры работ:

Заключение
В заключении можно сказать, что нейросети для обработки изображений имеют множество применений и представляют собой важный инструмент в различных областях.
При выборе нейросети для конкретной задачи необходимо учитывать ее характеристики и примеры ее работ.
Однако, все перечисленные в статье нейросети являются достаточно мощными и могут быть использованы для решения широкого круга задач.