Модели OpenAI Generative Pre-trained Transformer (GPT) — это серия языковых моделей на основе архитектуры трансформеров, обученных на большом корпусе текстовых данных для генерации человекоподобного текста, разработанных OpenAI. С момента появления трансформерной модели OpenAI продолжает оптимизировать GPT-модели, используя все большие и лучшие наборы данных, улучшенные модули нейронных сетей, контроль и помощь человека и другие инновации.
По состоянию на 2023 год, последняя модель GPT, Chat GPT, стала самым популярным приложением в мире, которое помогает пользователям решать проблемы в различных специализированных областях. В этой статье я хотел бы обсудить эволюцию моделей OpenAI GPT и их технические детали.
Есть несколько предпосылок для понимания эволюции GPT, включая модель трансформера, языковое моделирование и тонкую настройку под конкретные задачи обработки естественного языка.
Моделирование языка
Языковая модель — это распределение вероятности по последовательностям переменных токенов:
W = {W1, W2, W3, ⋯ , Wn} , а именно, P (W) = P (W1, W2, W3, ⋯ , Wn)
Чтобы оптимизировать такую языковую модель таким образом, чтобы язык, выбранный из распределения вероятности, был естественным для человека, обычно мы обучаем модель на текстовых данных, созданных человеком.
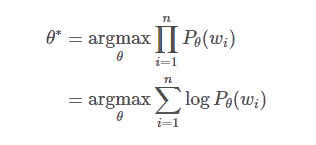
Оптимизация для большинства языковых моделей — это оценка максимального правдоподобия в отношении параметров модели с учетом текстовых данных обучения. Конкретно,
где θ — параметры языковой модели, n — количество последовательностей из набора данных, wi это i-я последовательность из набора данных.
Предположим, что W = {W1, W2, W3, ⋯ , Wn}, в соответствии с правилом цепочки,
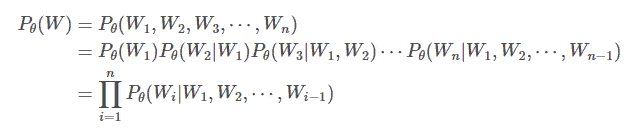
На практике языковые модели, такие как рекуррентные нейронные сети и трансформерные модели, оптимизируются по следующей формуле.
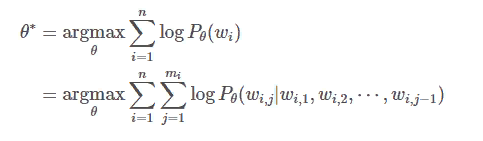
где mi — количество лексем в последовательности wi, а wi,j — j-я лексема в последовательности wi.
Тонкая настройка для конкретных задач обработки естественного языка
Существуют специализированные модели и наборы данных, разработанные специально для определенных задач обработки естественного языка, таких как распознавание именованных объектов (NER), машинный перевод (MT) и вопросы-ответы (QA). Каждая информация из набора данных состоит из пары входов X и выходов Y .
Оптимизация модели — это процесс обучения под наблюдением, который минимизирует ожидание потери предсказания. Конкретно,
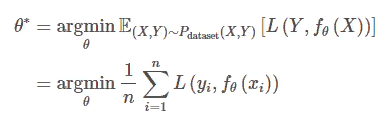
где n — количество данных из набора данных, а (xi,yi) — i-е аннотированные данные из набора данных.
OpenAI GPT-1
GPT-1 — это первое поколение GPT-моделей, которые OpenAI разработал для задач обработки естественного языка в 2018 году. Основным выводом из этой модели и статьи «Improving Language Understanding by Generative Pre-Training» стало то, что больше нет необходимости разрабатывать специальные архитектуры нейронных сетей для конкретных задач обработки естественного языка, а для конкретных задач обработки естественного языка достаточно трансферного обучения на основе авторегрессионной трансформационной декодерной языковой модели, предварительно обученной на большом корпусе текстовых данных.
Подобно авторегрессионным рекуррентным нейронным сетям, которые ранее были золотыми моделями для моделирования языка, очень просто обучить авторегрессионный трансформер-декодер, используя большой набор данных естественного языка в режиме самоконтроля.
Преимущество трансформера для языкового моделирования заключается в том, что количество лексем, используемых для обучения и вывода в трансформерной модели, может быть гораздо больше.
В отличие от рекуррентных нейронных сетей, обычно пользователю трансформера не нужно беспокоиться о том, что градиент уменьшается из-за эффекта обратного распространения во времени, что часто происходит при обучении рекуррентной нейронной сети, или что модель не может запомнить ранний контекст, что часто происходит при выводе рекуррентной нейронной сети, из-за слишком большого количества лексем для обучения или вывода (декодирования).
Это делает трансформер гораздо лучшей архитектурой для языковой модели и других задач обработки естественного языка, требующих понимания контекста текста.
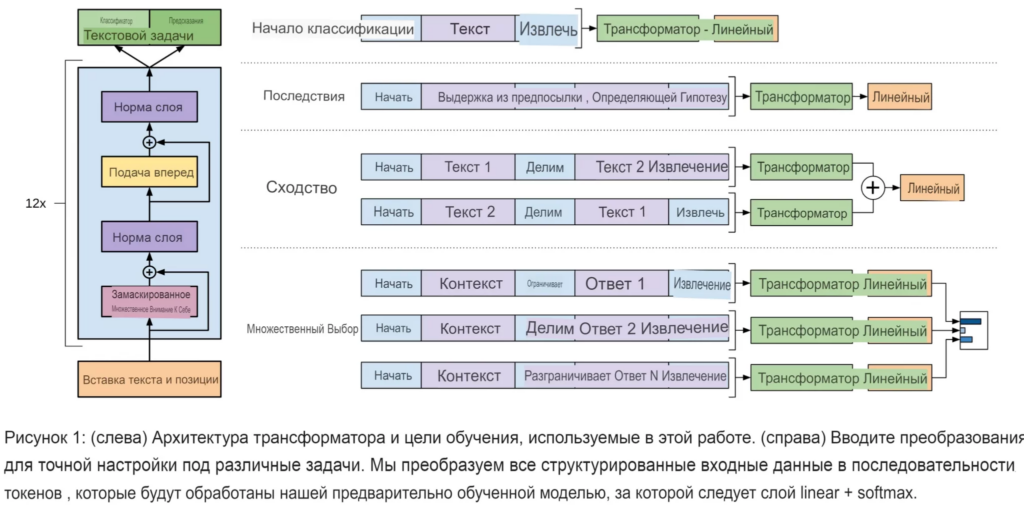
GPT-1 была сначала обучена как авторегрессионная языковая модель. Несмотря на то, что это авторегрессионная языковая модель в момент вывода для производства естественных языков, ее обучение не является авторегрессионным, и ее вывод также не обязательно должен быть авторегрессионным. Благодаря этому авторегрессионная языковая модель GPT-1 может быть доработана для специализированных задач обработки естественного языка с помощью специализированных наборов данных и методов, показанных на рисунке выше.
GPT-1 — это авторегрессионная модель декодера Transformer, в то время как в то же время существовала и неавторегрессионная модель кодера Transformer от Google под названием BERT, которая также была сначала обучена с помощью языкового моделирования (хотя языковое моделирование было «масочным»), а затем доработана под конкретные задачи обработки естественного языка с помощью специализированных наборов данных.
Авторегрессивная модель декодера Transformer использует механизм маскированного внимания, когда каждая лексема может обращать внимание только на предыдущие лексемы, тогда как неавторегрессивная модель кодера Transformer использует механизм немаскированного внимания, когда каждая лексема может обращать внимание на лексемы до и после себя двунаправленно.
Таким образом, кажется, что для специализированных задач обработки естественного языка, чьи входы X всегда даны заранее, BERT имеет больше смысла, чем GPT-1. На самом деле, если я правильно помню, BERT был более популярен, чем GPT-1, и был самым современным для различных задач обработки естественного языка в то время.
Следует также отметить, что в то время для задач обработки естественного языка, таких как QA, формулировка проблемы в моделировании казалась мне очень неудобной, хотя производительность моделей, таких как BERT, в то время была очень хорошей. Например, несмотря на то, что QA означает «вопрос и ответ», формулировка проблемы в моделировании была фактически обнаружением ответа, т.е. обнаружением ответов из контекста путем предсказания индекса начальной и конечной лексемы в контексте, вместо интеллектуального ответа. Проблемы такого рода были решены в более поздних моделях GPT.
OpenAI GPT-2
GPT-2 — это второе поколение моделей GPT, которые OpenAI разработала для задач обработки естественного языка в 2019 году. Это модель, которая впервые имеет более одного миллиарда параметров. Благодаря огромным инженерным усилиям OpenAI (и NVIDIA GPU), GPT-2 продемонстрировала возможности больших немаркированных высококачественных текстовых наборов данных и потенциал модели для решения различных специализированных задач обработки естественного языка, таких как QA и Translation, с помощью языкового моделирования с нулевым результатом. Это также резюмируется в статье под названием «Языковые модели — несамостоятельные многозадачные обучаемые«.
В этой работе OpenAI создал чрезвычайно большой набор данных с предостережениями относительно его качества. Поскольку набор данных настолько велик, он уже содержит множество «аннотированных» примеров для различных специализированных задач обработки естественного языка.
Например, набор данных может содержать фрагмент текста «Перевод слова «Hello» на китайский язык — «你好», который является идеальным примером для машинного перевода с английского на китайский. Используя этот набор данных для обучения языковой модели, если модель обладает достаточным потенциалом и способна к обобщению, она будет очень хорошо справляться со специализированными задачами обработки естественного языка.
Например, для задачи QA, когда контекст и вопросы были загружены в GPT-2, модель больше не должна отвечать на вопросы путем обнаружения, она просто отвечает путем генерации новых лексем, что более похоже на поведение человека. Что еще более важно, чем больше модель, тем лучше ее производительность для различных задач.
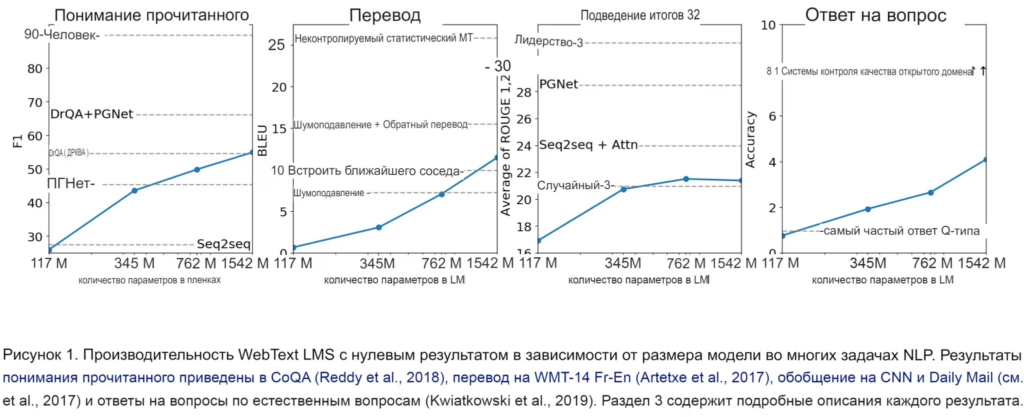
В работе над GPT-2 разработчики фактически начали использовать инструкции, позже названные подсказками, чтобы направить языковую модель на генерацию нужного текста. Например, вопрос в задаче QA является естественной подсказкой; подсказка «TL;DR:» разработана в наборе данных для обучения задачам обобщения текста.
Также стали использоваться примеры, чтобы направлять языковую модель на выполнение нужных задач, например, добавление примера перевода с английского на французский перед английским предложением, которое нужно перевести, чтобы попросить языковую модель выполнить перевод с английского на французский, что становится очень распространенным подходом в более поздней модели GPT-3.
OpenAI GPT-3
GPT-3 — это второе поколение моделей GPT, которые OpenAI разработала для задач обработки естественного языка в 2020 году, и оно было феноменальным. Количество параметров GPT-3 превышало 175 миллиардов, что в 175 раз больше, чем у GPT-2.
Исследование GPT-3 естественным образом расширило GPT-2. В его работе «Языковые модели — это обучающиеся на нескольких снимках» подчеркивается «обучение в контексте», которое заключается в том, что просто показав несколько демонстраций (несколько снимков), заданных в качестве входных данных, языковая модель может работать намного лучше в специализированных задачах обработки естественного языка во время вывода, без необходимости обновления параметров модели.
Например, чтобы попросить GPT-3 сделать машинный перевод, мы можем сначала описать задачу, затем показать несколько демонстраций и, наконец, дать подсказку, то есть предложение, которое нужно перевести GPT-3, и GPT-3 может сгенерировать переведенное предложение.
На самом деле, мы уже видели некоторые из таких примеров в работе GPT-2, упомянутой ранее.

В дополнение к этому, GPT-3 использовал механизм разреженного внимания, уменьшая асимптотическую сложность вычисления матриц внимания с O(N2) на O(N√N). Это в некоторой степени уменьшило давление на вывод модели с 175 миллиардами параметров.
OpenAI InstructGPT
Несмотря на то, что языковые модели GPT, включая GPT-3, до сих пор отлично справлялись со специализированными задачами обработки естественного языка. Они не обучены выполнять человеческие инструкции, поскольку набор данных, который использовался для обучения моделей GPT ранее, содержит меньше такого текста.
Инструкция — это не всегда вопрос, и она может не иметь богатого контекста, чтобы модели было легче следовать инструкции.
Раньше, чтобы выполнить задачу QA в GPT-3, мы должны были сначала предоставить документ, затем вопрос и некоторые специальные лексемы, такие как «A:» или «Answer:». Это не естественный способ, которым люди просят людей отвечать на вопросы. Особенно для некоторых вопросов нам не нужно сначала предоставлять документ.
Например, если пользователь просто попросил языковую модель GPT-3 «Объяснить высадку на Луну 6-летнему ребенку в нескольких предложениях», не давая больше контекста или демонстрации. GPT-3 вряд ли поймет, что это инструкция от человека. Поэтому GPT-3 может генерировать такие предложения, как «Объясните шестилетнему ребенку теорию гравитации» или «Объясните шестилетнему ребенку теорию большого взрыва». С точки зрения естественного языка, эти завершения имеют смысл. Но с точки зрения человека, языковая модель не справилась с задачей, которую мы ожидали.
В дополнение к проблеме следования инструкциям человека, язык может генерировать вредные или фальшивые тексты. Например, с точки зрения естественного языка, для языковой модели совершенно нормально генерировать «Я хочу уничтожить людей», особенно когда большой набор данных, использованный для обучения, никогда не может быть полностью и серьезно изучен разработчиками OpenAI. Но это предложение очень токсично для людей-читателей.
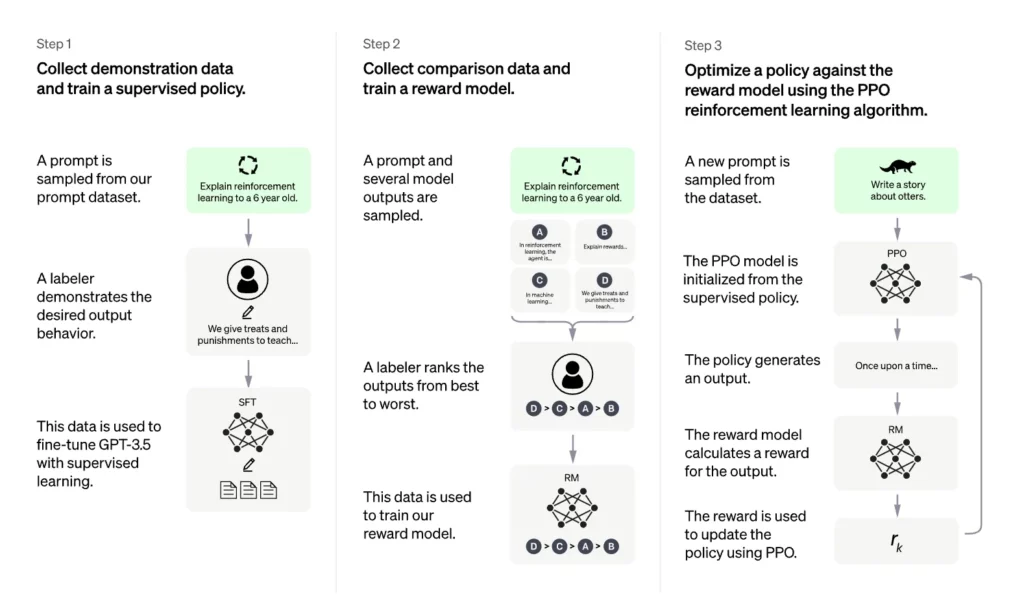
InstructGPT был разработан специально для решения этой проблемы в 2022 году. В процессе обучения InstructGPT человек участвует в цикле. Процедура обучения может быть представлена следующим образом:
- Собираются демонстрационные данные, которые представляют собой набор данных, состоящий из подсказки и соответствующего желаемого ответа, продемонстрированного человеком. Предварительно обученная модель GPT-3 затем дорабатывалась на этом наборе данных с помощью супервизорного обучения. Эта модель обозначается как модель с контролируемой тонкой настройкой (SFT).
- Сбор сравнительных данных. Каждая информация из набора данных сравнения состоит из подсказки, нескольких примеров завершений из модели тонкой настройки, ранжирования завершений человеком на основе его предпочтений. На этом наборе данных была обучена модель вознаграждения (RM), которая будет предсказывать оценку вознаграждения по подсказке и завершению.
- Дальнейшая оптимизация модели SFT в среде обучения с подкреплением с использованием вознаграждения, генерируемого RM и алгоритма оптимизации проксимальной политики (PPO). Те модели STF, которые были дополнительно оптимизированы с помощью алгоритма PPO, обозначаются как модели PPO.
Обратите внимание, что шаги 2 и 3 могут быть итерированы в цикле обучения.
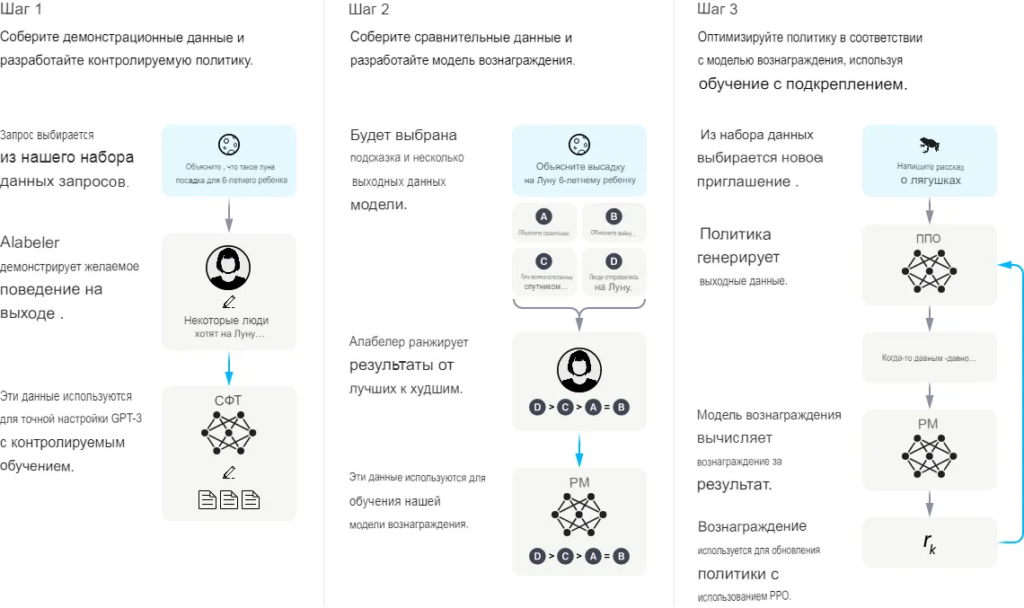
Шаг 1 выглядит очень простым для того, кто знаком с обучением языковых моделей. Шаг 2 и шаг 3 немного туманны из краткого описания. Остановимся на них подробнее.
На шаге 2 RM — это, по сути, еще одна модель архитектуры GPT-3, состоящая из чуть меньшего количества параметров. Она предварительно обучена на наборе текстовых данных и специализированных задачах обработки естественного языка, а затем доработана на основе собранных сравнительных данных.
К архитектуре GPT-3 была прикреплена регрессионная головка, чтобы она могла выдавать скалярную оценку вознаграждения, учитывая входные данные подсказки и завершения, точно так же, как OpenAI настраивала GPT-1 для конкретных задач естественного языка.
Потери при ранжировании были разработаны таким образом, чтобы модель RM могла научиться предсказывать скалярные оценки вознаграждения, используя набор данных ранжирования, в котором нет истинного вознаграждения. А именно,
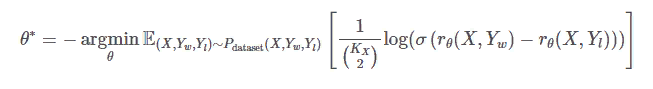
где KX это количество завершений, которые человек проранжировал для подсказки X,rθ( X , Y ) скалярный выход РМ для подсказки X и завершения Y, σ является сигмоидной функцией, Yw и Yl являются парой завершений для X и Yw
является предпочтительным.
Обратите внимание, что приведенное выше выражение оптимизации немного отличается от того, что описано в статье InstructGPT «Training Language Models to Follow Instructions with Human Feedback«, потому что я считаю, что их выражение не совсем корректно и может запутать читателей.
Кроме того, я не совсем верю в их объяснение чрезмерной подгонки RM, если они перемешали сравнения в один набор данных вместо того, чтобы сгруппировать все сравнения для одной подсказки в один пакет в статье InstructGPT. Вполне вероятно, что они, сами того не подозревая, провели следующую оптимизацию, которая испортила процесс обучения.
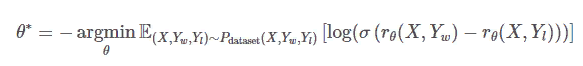
Фиксируя функцию потерь, они могут оптимизировать модель тем же способом без перебора, даже если они перемешают сравнения в один набор данных.
На этапе 3, учитывая подсказку X, модель PPO πRL/ϕ, где ϕ — параметр модели, может случайным образом выбрать завершение Y с вероятностью πRL/ϕ (Y|X). Вероятность того, что одна и та же пара подсказки и завершения будет выбрана из модели SFT с шага 1, πSFT(Y|X), также может быть вычислена. RM может генерировать вознаграждение для пары подсказки и завершения rθ(X, Y). Поскольку PPO также является языковой моделью, для любого заданного текста на естественном языке входные данные W она может вычислить его вероятность πRL/ϕ(W).
Оптимизация модели PPO с помощью PPO заключается в максимизации следующей цели, которая состоит из трех частей.
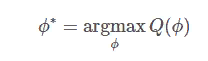
и
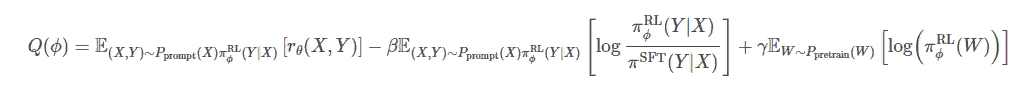
где β и γ это весовые коэффициенты для различных компонентов.
Первый компонент в цели максимизации, E(X, Y)∼Pprompt (X) πRL/ϕ(Y|X)[rθ(X, Y)] , является простым для понимания.
Мы хотели бы, чтобы модель PPO генерировала завершение Y, учитывая любое X таким образом, чтобы вознаграждение rθ(X, Y) максимизируется. Это также называется оптимизацией «политики», что является термином в обучении с подкреплением. Этот компонент является основным в цели оптимизации.
Второй компонент в цели максимизации, E(X, Y)∼Pprompt (X) πRL/ϕ(Y|X)πRL/ϕ[logπRL/ϕ(Y|X)/πSFT(Y|X)] является регуляризирующим членом, который гарантирует, что политика модели PPO не отклоняется от политики модели SFT. Фактически, этот компонент является просто KL-расхождением и называется «штраф KL на токен», упоминаемый в статье.
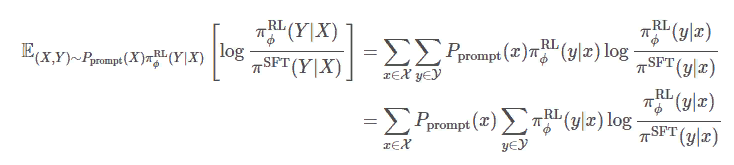
На самом деле, я думаю, что было бы более уместно называть это штрафом KL на подсказку вместо штрафа на токен в статье.
Помните, что дивергенция KL строго неотрицательна, и ее значение равно 0 тогда и только тогда, когда два распределения абсолютно одинаковы. Вот почему
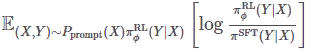
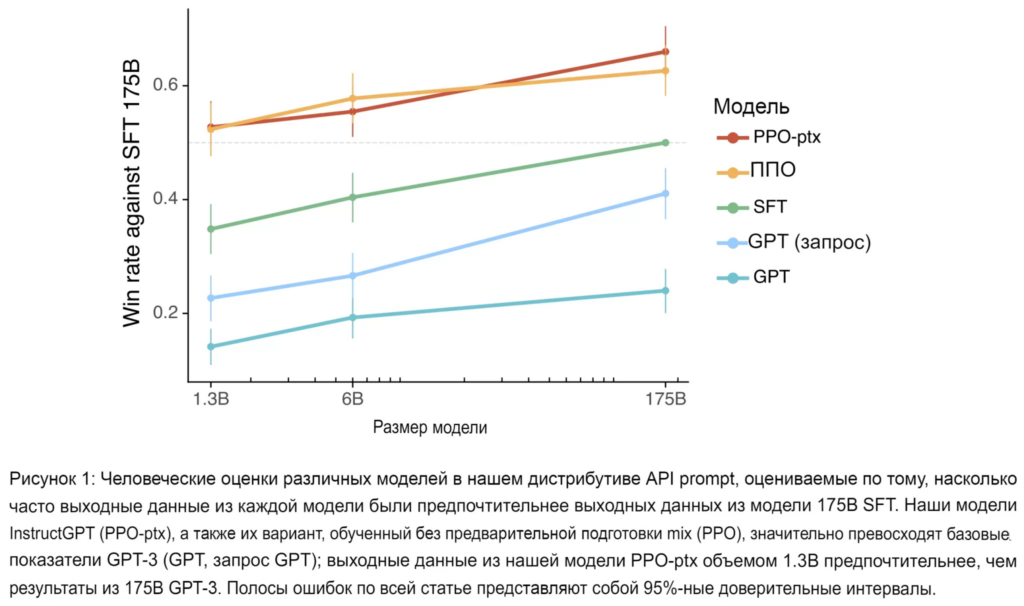
является регуляризационным членом, который гарантирует, что политика модели PPO не отклоняется от политики модели SFT. В конце концов, SFT уже должна хорошо следовать инструкциям человека, что также продемонстрировано на следующем рисунке.
Третий компонент — типичный термин, используемый для языкового моделирования.
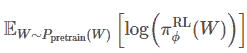
Напомним, что модель PPO также является языковой моделью. Это гарантирует, что политика генерации модели PPO не будет сильно отклоняться от языковой модели, чтобы просто максимизировать значение вознаграждения, особенно учитывая, что RM никогда не может быть безупречным.
OpenAI ChatGPT
ChatGPT был развитием InstructGPT, который OpenAI разработал в 2022 году. Процесс его обучения был практически таким же, как и InstructGPT, подробно описанный выше, за исключением того, что демонстрационные данные, используемые для обучения SFT-модели ChatGPT, отличались от тех, что используются для обучения SFT-модели InstructGPT.
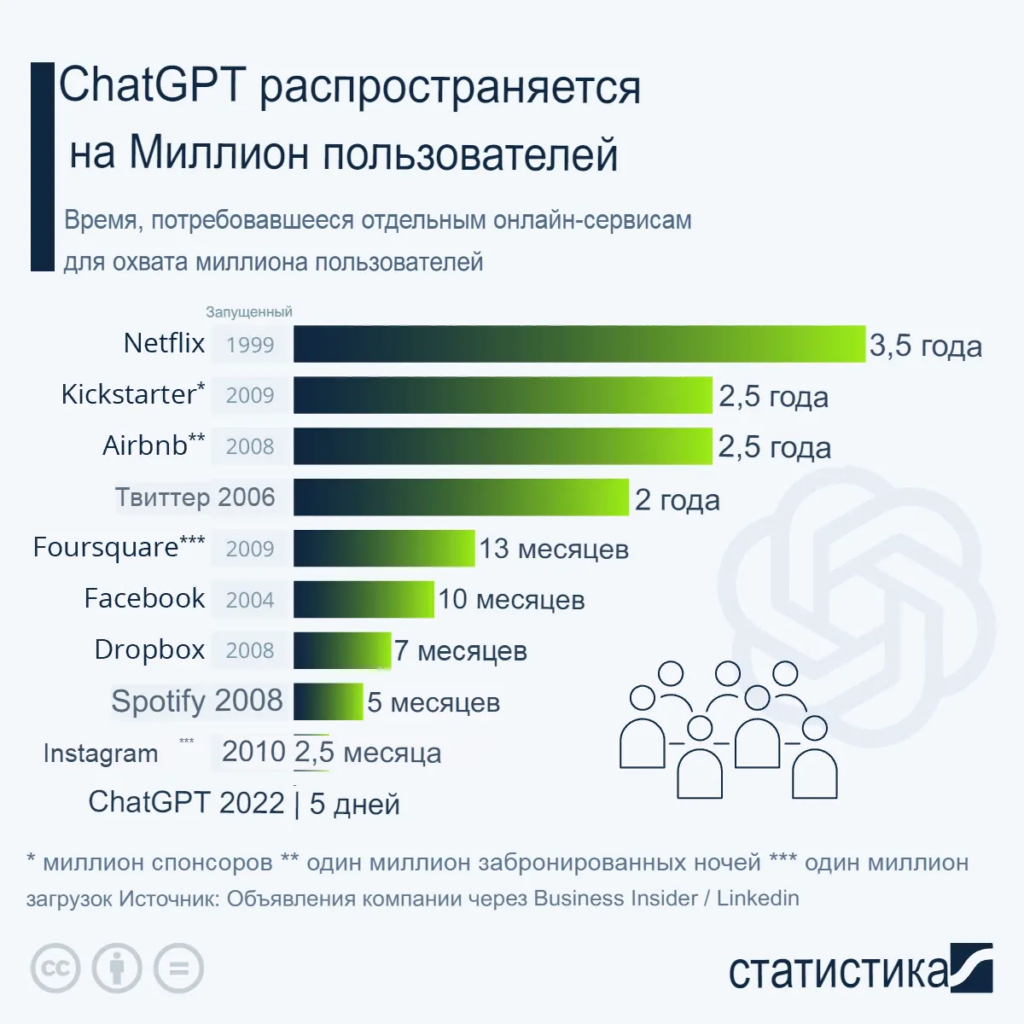
Как можно понять из названия, ChatGPT — это приложение, которое позволяет пользователю общаться с искусственным интеллектом. Но «интеллект», который ChatGPT демонстрировал в различных областях, был настолько поразительным, что многие люди начали опасаться потерять работу из-за ChatGPT. Из-за этого оно сразу же стало самым популярным и быстрорастущим приложением в истории.
Разница между ChatGPT и InstructGPT заключается в том, что InstructGPT больше похож на «одноразовый», когда пользователь дает одну инструкцию, а InstructGPT выполняет работу, в то время как ChatGPT позволяет этому процессу быть итеративным в форме разговора, не забывая о предыдущем контексте. Он позволяет пользователю задавать вопросы или давать инструкции, а также уточнять вопросы или инструкции.
Производительность ChatGPT, также очень приятна. Поскольку ChatGPT может помочь пользователю сделать что-то и непосредственно подсказать ответ, зависимость человека от поисковой системы может быть значительно снижена. В связи с этим Google даже выпустил «красную тревогу», которую он никогда не выпускал с момента своего основания.
Наконец, давайте посмотрим, что отличает ChatGPT и InstructGPT — данные. Данные, используемые для обучения модели SFT в ChatGPT, представляют собой диалоги, созданные людьми в специальном формате диалога. Ответы в диалоге могут быть предложены существующими моделями GPT и уточнены человеком. Поэтому, когда ChatGPT обучается, он остается таким же интеллектуальным, как InstructGPT, и имеет лучший пользовательский опыт, поскольку процесс становится итеративным диалогом.
Выводы
Идеи моделей OpenAI GPT просты, но чрезвычайно затратны. К счастью, как показали результаты, они также эффективны. История GPT-моделей показала решимость и исполнительность OpenAI в продвижении искусственного общего интеллекта (AGI) с помощью естественного языка, чего, вероятно, не было ни у кого другого.
В будущем, по крайней мере, в ближайшем будущем, я могу представить, что путь людей к искусственному интеллекту будет (все еще) основан на больших искусственных нейронных сетях, управляемых большими аннотированными наборами данных, и с помощью людей.
Как показали InstructGPT и ChatGPT, языковые модели начали становиться действительно полезными и универсальными только тогда, когда в дело вступили аннотированные базы данных и человеческий контроль.
Источники: