Чему новому научились нейросетевые модели вроде Chat GPT и почему они вот-вот оставят лично вас без работы. При этом мало кто понимает, а как они вообще устроены и что у них внутри.
Сегодня я вам расскажу все так, чтобы понял даже шестилетний гуманитарий. Поехали!
- T9: языковая модель в телефоне
- Откуда нейросети берут вероятности слов?
- Основная задача при тренировке модели чат-бота
- Чат GPT 2018: GPT-1 и архитектура Трансформера
- 2019: GPT-2 или 7000 Шекспиров в нейросети
- Как измеряется сложность и размер моделей
- 2020: GPT-3, или Невероятный Халк
- Промпты, или как правильно уламывать модель
- Январь 2022: InstructGPT
- Ноябрь 2022: ChatGPT – хайпуют все!
T9: языковая модель в телефоне
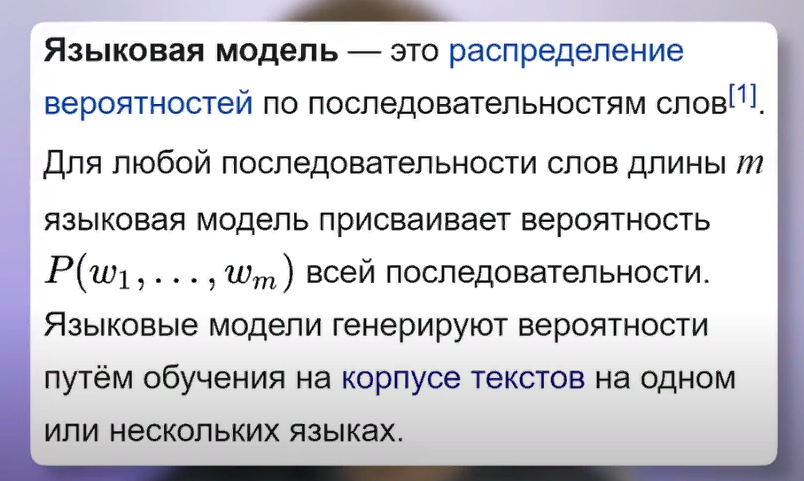
Начнем с простого. Приготовьтесь услышать страшную правду. На самом деле ChatGPT это Т9 из вашего телефона, но на бычьих стероидах. Да, это так, ученые называют обе этих технологии языковыми моделями, т.е. language models. А все, что они делают, это по сути угадывают следующее слово, которое должно следовать за уже имеющимся текстом.
Ну, точнее, об совсем олдовых телефонах из конца 90-х, вроде неубиваемой Nokia 3310 культовой, Т9 он только помогал набирать текущее слово, а не следующее. Но уже к началу 2010-х в смартфонах технология развивалась, и она стала позволять ставить пунктуацию, учитывать контекст и как раз таки угадывать слово, которое могло бы следовать следующим.
Вот как раз об аналогии с такой более продвинутой версией автозамены и идет речь. Итак, и Т9 на клавиатуре смартфона, и чат GPT обучены решать до безумия простую задачу – предсказывать одно следующее слово, которое следует за уже имеющимся текстом. Это и есть, собственно, языковое моделирование.
Чтобы иметь возможность сделать такие предсказания, моделям нужно оперировать вероятностями следующих слов. Ну, ведь, скорее всего, вы были бы разочарованы, если бы вам смартфон подкидывал абсолютно рандомные слова в автозаполнении для продолжения того, что вы печатаете.
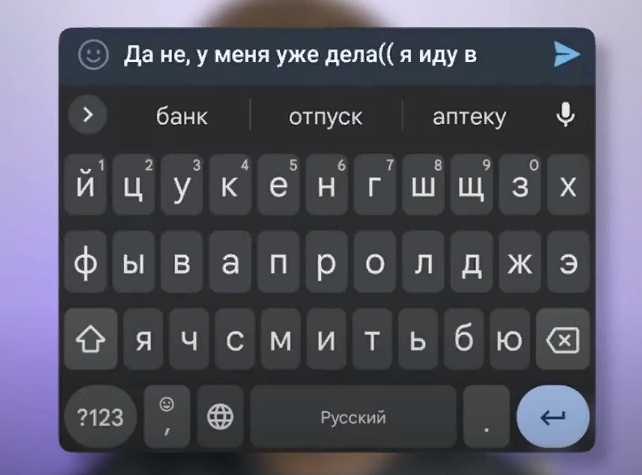
Ну, представим для наглядности, что вам прилетает сообщение от приятеля «Чё, гость сегодня куда-нить ?» А вы ему начинаете отвечать «Да не, сори, я уже иду в…». И вот если в этот момент вам смартфон подскажет закончить предложение словом «Я уже иду в Кэпибару», предположим, то для такой билиберды, если честно, никакие хитрые языковые модели и не нужны. Можно было бы просто из словаря рандомное слово подставлять.
Но вы же ожидаете, что вам смартфон подскажет что -то более разумное. И действительно, если вы прямо сейчас попробуете набрать эту фразу «Да блин, нет, у меня уже дела, я иду в…» и посмотрите, что вам подсказывает смартфон, вы, скорее всего, увидите какие-то вполне адекватные продолжения. Ну, например, «Я иду в банк», «В отпуск» или «Я иду в аптеку».
Так, а как конкретно Т9 понимает, какие слова могут следовать с большой вероятностью за набираемым текстом, а какие предлагать точно не стоит? Для ответа на этот вопрос нам придется погрузиться в базовые принципы работы самых простейших нейросеток.
Откуда нейросети берут вероятности слов?
А как вообще предсказывать зависимость одних вещей от других? Ну, предположим, что мы хотим научить некую математическую модель предсказывать зависимость веса человека от его роста.
Как подойти к этой задаче?
Ну, здравый смысл подсказывает, что нужно сначала собрать некий массив данных, на которых мы будем искать закономерности. Давайте для простоты ограничимся только одним полом и рассмотрим только мужчин. Возьмем статистику для нескольких тысяч мужиков по росту-весу и попробуем натренировать матмодель, чтобы она нашла зависимость. Для наглядности давайте сначала нарисуем весь наш массив данных на графике.
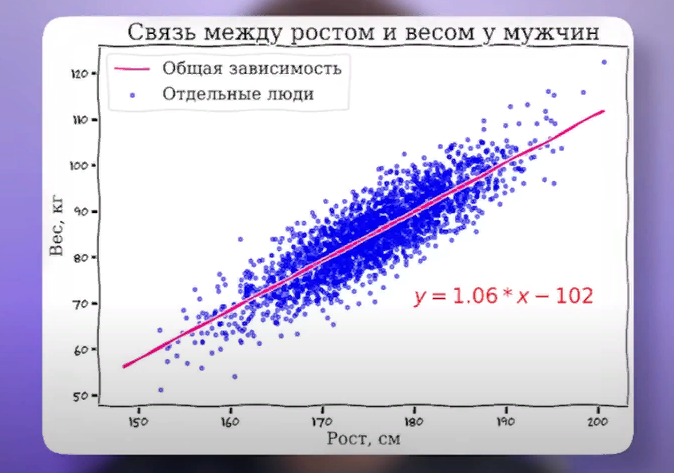
По оси х будем откладывать рост человека, а по оси у его вес. Ну и невооруженным взглядом видна определенная зависимость. Высокие мужики больше весят, спасибо КЭП. Причем эту зависимость довольно просто вырезать простым линейным уравнением, которое нам всем знакомо по пятому классу школы y равно kx плюс b. Причем такая штука как линейная агрессия нам позволяет выбрать уравнение, которое наилучшим оптимальным образом описывает эту зависимость.
На картинке она уже проведена. При этом вы можете прямо сейчас попробовать подставить в это уравнение свой рост и посмотреть, предскажет ли оно ваш вес. Мой не очень хорошо предсказывает, потому что выборка на довольно-таки упитанных мужиках построена.
Возможно речь идет про американцев, не знаю. Вы уже наверняка хотите воскликнуть. Окей, с ростом весом в общем-то и так все интуитивно было понятно.
Но при чем же здесь текстовые языковые модели?

А при том, что нейросети это и есть набор примерно таких же точных уравнений, только гораздо более сложных и использующих матрицы. Об этом мы сейчас подробно говорить не будем.
Можно упрощенно сказать, что Т9 или ЧАТ-ГПТ – это просто набор огромного количества уравнений, где хитрым образом подобраны коэффициенты при иксах. Иксы в данном случае – это слова, которые подаются на вход модели, а Y – это как раз то самое следующее слово, которое модель пытается предсказать.
Основная задача при тренировке модели чат-бота
Основная задача при тренировке модели – это как раз подобрать вот самые правильные коэффициенты при иксах, которые позволят хорошо предсказывать зависимость, хорошо ее выражать. Примерно так же, как мы подбирали коэффициенты для нашего уравнения по росту весу.
А под большими моделями ученые понимают такие, где очень много параметров, то есть очень много иксов уравнений. Они прямо так и называются LLM – Large Language Models. И как мы дальше увидим, чем жирнее модель, чем больше у нее параметров, тем она круче генерирует тексты. Кстати, если в этом месте вы недоумеваете, почему мы все время говорим о предсказании одного следующего слова, при том, что chat gpt вполне бодро выплевывает целые протянки текста, то не печальтесь, здесь все просто.
Да, действительно нейросетка может генерировать целый текст, но делает она это слово за словом. То есть она каждый
раз выплевывает следующее слово, потом как бы подает сама на себя на вход весь текст с учетом предыдущего
слова и генерирует следующее. И таким образом получается вполне себе связанный текст.
На самом деле в наших уравнениях в качестве Y языковые модели пытаются предсказать не столько конкретное следующее слово, почему языковые модели умеют в творчество, сколько вероятности разных слов, которые могут следовать за текущим текстом.
Зачем это нужно? Почему нельзя вот просто всегда использовать одно, самое правильное слово? Давайте разберем на конкретном примере.
Будем играть в небольшую игру, вы будете притворяться языковой нейросетью, а я вам буду давать задания.
Итак, продолжите предложение: 44-й президент США и первый афроамериканец на этой роли это Барак. Теперь ваша очередь. Попытайтесь угадать, какое будет следующее слово и с какой вероятностью оно там окажется.
Если вы сейчас сказали, что следующим словом должно идти Обама с вероятностью 100%, то поздравляю, вы ошиблись. Дело тут не только в том, что есть какой -то другой мифический Обама-президент Барак. Нет, просто у него есть второе имя, так называемый Хусейн, и в официальных документах его часто пишут полностью Барак, Хусейн, Обама.
Соответственно, правильно настроенная нейросетевая модель должна была сказать, что Обама за Бараком следует, ну, процентах в 90 случаев, а 10 % оставить на то, что там сначала будет Хусейн, ну и потом завершится все почти
точно Обамой. И тут мы с вами подходим к интересному аспекту этих самых нейросетевых моделей.
Оказывается, им не чужда творческая жилка. Ну, то есть, по сути, при генерации следующего слова модель каждый раз как бы кидает кубик, чтобы его выбрать, но не абы как, а так, чтобы вероятности выпадения разных слов примерно соответствовали тем самым вероятностям, которые модель оценила с помощью собственных уравнений.
Ну и при этом получается, что одна и та же модель может на совершенно одинаковые запросы давать разные ответы, то есть она может придумывать разные варианты совсем как человек. При этом ученые, они раньше пытались сделать
так, чтобы модель все время выбирала одно самое вероятное слово, но почему -то результаты были не такие хорошие.
Модели часто путались, начинали циклично ходить по кругу, а вот если им сделать специальную функцию, которая позволяет иногда вариативность проявлять, выбирать разные слова, то в этом случае получается очень классно, ответы получаются насыщенные, интересные, и вообще модель выглядит совсем как человек уже.
Итак, краткое резюме: На текущий момент мы выяснили, что языковые модели применялись в функциях Т9 автозамены еще с начала 2010-х в смартфонах, и при этом они представляют собой набор уравнений, которые натренированы на предсказании одного следующего слова, которое следует за уже существующим текстом.
Давайте уже переходить от всяких дремучих Т9 к более современным моделям.
Чат GPT 2018: GPT-1 и архитектура Трансформера
Наделавший столько шума чат GPT, 2018: GPT-1 и архитектура Трансформера является наиболее современным представителем семейства моделей GPT.
GPT здесь это Generative Pre-trained Transformer, или трансформер, обученный на генерацию текста. И трансформер в данном случае – это не отсылка к фильму Майкла Бэя или аниме-мультикам старым, а архитектура нейросети, которую придумали исследователи Google в далеком 2017 году. И когда я говорю «в далеком», я не шучу.
По меркам индустрии, прошедшей с тех пор шесть лет, это просто целая вечность. Именно изобретение трансформера стало таким знаковым событием для всей индустрии искусственного интеллекта.
Вообще все области ИИ – от обработки текста, изображения, звука, видеопереводов и так далее – они все стали активно пользоваться именно эту технологию. И вообще можно сказать, что вот тот застой, так называемая «зима искусственного интеллекта», которая царила до выхода этой новой технологии, она вот именно с помощью трансформера и была преодолена. И вообще весь расцвет, который мы видим, это все благодаря трансформерам в первую очередь.
Концептуально трансформер – это такой универсальный вычислительный механизм, который очень просто описать. Он принимает на вход один набор последовательностей данных и выдает на выходе другой набор последовательностей, но уже преобразованный по некоему алгоритму.
И так как текст, картинки, звук, да и вообще почти все в этом мире можно представить в виде последовательностей циферок, то получается, что трансформер может практически любые задачки помогать решать. Но главная фишка трансформера заключается в его удобстве и масштабируемости, потому что он состоит из очень простых модулей блоков, которые легко комбинировать между собой и легко масштабировать.
И вот старые до-трансформерные нейросетевые модели, они начинали кашлять и кряхтеть, когда их пытались заставить слишком быстро или слишком много слов проглотить за раз. А вот новые нейросети-трансформеры, они без проблем обрабатывают огромные массивы данных, справляются с этим гораздо лучше.
Более ранним подходом приходилось обрабатывать текст по принципу один за одним, то есть последовательно.
И вот такая модель простая, она когда проглатывала большой текст, то она уже к середине третьего абзаца начинала
забывать, а что там было в начале, ну прямо как люди с утра до того, как они бахнули кофейку. А вот могучие лапища трансформера позволяют ему смотреть на все и сразу одновременно, и это приводит к гораздо более впечатляющим результатам.
Именно это и позволило сделать прорыв в генерации текстов. И для примера давайте посмотрим на простой текст.
Шла Саша по шоссе и сосала. И вот если вы этот текст запихнете, например, в Т9, в автозаполнение в телефоне, то там, скорее всего, модель совсем простая, и она вам предложит, что сосала Саша такое, что даже Саша грей покраснеет. А вот если вы в какой-нибудь чат G5 тот же самый текст засунете, чат G5 скажет, так это же поговорка. Саша сосала сушку, и все нормально.
Поэтому новые современные трансформерные нейросетки, они гораздо более хорошо держат контекст, не забывают вообще, что там было в начале предложения, и вообще гораздо круче генерируют тексты. Краткое резюме. GPT -1 появилась в 2018 году и доказала, что для генерации текстов нейросетью можно использовать архитектуру трансформера, обладающую гораздо большей масштабируемостью и эффективностью.
И это создало огромное задел на будущее по возможности наращивать объем и сложность языковых моделей.
2019: GPT-2 или 7000 Шекспиров в нейросети
Если вы хотите научить нейросетку для распознавания изображений, 2019: GPT-2 в нейросети отличать маленьких милых чеклабелей от маффинов с черничкой, то вы не можете просто кинуть в нее архив на 100-500 тысяч фотографий и сказать ей, ну вот там разбирайся короче сама, вот пример чеклабелей, вот пример булочек. Типа все будет понятно.

Нет. Вам нужно еще этот огромный массив разметить, то есть под каждой фоткой подписать какая из них является пушистой, а какая сладкой, иначе никакой тренировки у вас не получится.
А знаете, чем прекрасно обучение больших языковых моделей? Тем, что их можно тренировать на совершенно любом наборе текстовых данных, которые сделал человек, и не нужно их никак перед этим заранее размечать.
Это как если бы в школьника можно было бы кинуть просто чемодан с учебниками и не говорить ему, что в каком порядке читать, а он бы это изучал и что -то там для себя кумекал бы, какие-то выводы хитрые. И если подумать, то это логично. Мы же хотим научить нейросетевую модель предсказывать следующее слово на основании предыдущих слов.
Так вот, любой совершенно текст, который написал человек, это и есть огромный набор таких как раз-таки последовательностей, когда ты берешь какие-то слова и потом просто смотришь, а какое слово шло следующим за ними. А теперь давайте еще вспомним, что обкатанная технология трансформеров на GPT-1, она оказалась на редкость эффективной в обработке огромных массивов данных и работе с большими моделями, то есть с такими, которые состоят из множества параметров.
Вы думаете о том же, о чем и я? Ну вот и ученые из компании OpenAI решили так же. Пришло время пилить здоровенные модели. В общем, было решено радикально прокачать GPT-2 по двум ключевым параметрам. Набор тренировочных данных, датасет и объем самой модели, то есть количество параметров у нее.
И на тот момент не было каких -то специальных тренировочных официальных наборов данных для исследователей искусственного интеллекта. Каждому приходилось извращаться, как он может.
Ну и вот ребята из OpenAI, они решили поступить достаточно остроумно. Они пошли на Reddit, это самый такой крупный англоязычный форум, и просто взяли и скачали все гиперссылки из всех сообщений, у которых было 3 лайка или больше.
Ну то есть вот типа научный подход буквально, да? И по этим всем гиперссылкам они просто скачали огромное количество текстов.
Ссылок получилось 8 миллионов, а текстов примерно 40 гигабайт. Много это или мало?

Ну давайте прикинем. Уильям Шекспир, вот такой вот известный поэт и писатель англоязычный, он написал всего 850 тысяч слов за свою карьеру по Давиду. В среднем на одной странице книги где-то около 300 английских слов помещается. Так что речь идет про 2800 примерно страниц прекрасного, немножко устаревшего англоязычного текста. Так вот, это все займет примерно 5,5 мегабайт памяти компьютера. И это в 7300 раз меньше, чем закачали в GPT-2.
С учетом того, что люди в среднем они читают примерно вот по странице в минуту, даже если вы будете поглощать текст 24 часа в сутки, без перерыва на еду, сон и так далее, то вам потребуется почти 40 лет, чтобы догнать GPT-2 по эрудиции довольно таки не кисло, согласитесь. Но одного объема тренировочных данных для получения крутой языковой
модели недостаточно. Она еще и должна быть достаточно сложной, чтобы его понять.
Ну представьте, даже если вы посадите пятилетнего ребенка читать все собрания сочинений Шекспира и вместе с ним все лекции Фейнмана по квантовой физике, то вряд ли он от этого станет сильно умным, ему просто мозгов не хватит все это осмыслить. Так и тут модель должна быть достаточно сложной, чтобы все это переварить. А в чем измеряется сложность модели? Давайте обсудим.
Как измеряется сложность и размер моделей
Помните, мы с вами говорили чуть раньше, что внутри языковых моделей в суперупрощенном приближении сидит набор
уравнений y равно kx плюс b, где иксы — это слова, подаваемые на вход, а y, соответственно, — это слово следующее, которое мы пытаемся найти и предсказать его вероятность.
Так вот, как вы думаете, сколько было таких иксов-параметров в уравнениях, которые описывали GPT-2 -модель, вышедшую в 2019 году? Может быть, там пара тысяч или пара миллиардов?
Берите выше. Таких параметров в уравнении было полтора миллиарда.
Это прям огромное количество. Если просто такое количество цифр записать в файл, сохранить его на диск, то это будет аж 6 гигабайт. При этом можно заметить, что это поменьше, чем объем данных, на котором мы тренировали нейросеть.
Помните, мы же там с Reddit-а выкачали аж 40 гигабайт. Но, с другой стороны, это логично. Модели же не нужно прям дословно заучить весь текст.
Нет, ей нужно просто определенный набор паттернов, правил и параметров вычленить из этого текста самую суть
зависимости, а сам текст запоминать дословно, в общем -то, необходимости и нет. При этом вот эти вот параметры, их еще называют коэффициенты или веса, их не нужно каждый раз переоценивать заново. При тренировке они оцениваются один раз и как раз-таки вот запоминаются в специальном файле.
А иксы, они каждый раз подаются новые. То есть вы, по сути, каждый раз, когда скармливаете нейросети, новый какой -то отрывок текста, она для того, чтобы предсказать следующее слово, просто в это гигантское уравнение каждый раз подставляет новые иксы, а коэффициенты, они остаются неизменными при этом.
Получается, что чем более сложные уравнения с большим количеством параметров зашиты внутри нейросетевой модели,
тем лучше она, тем более связанные тексты генерирует и так далее.

При этом даже вот у GPT-2, которая вышла в 2019 году, модель получилась настолько неожиданно хорошей, что ребята из OpenAI даже побоялись ее в открытую публиковать. Ну, потому что они решили, что можно сейчас эту нейросетку использовать, чтобы в промышленном количестве пилить огромное количество фейков и наводнить ими просто весь интернет.
Ну, серьезно, это прям был существенный прорыв такой. Вы же помните, что T9 или GPT -1, ну, они могли в лучшем случае там угадать, что Саша, которая по шоссе шла, она сосала сушку, а не что-то другое. Так вот, GPT -2 уже легко написала эссе от
имени подростка на тему, какие фундаментальные экономические и политические изменения необходимы для эффективного реагирования на изменения климата.
Ну, достаточно серьезная тема, даже многие взрослые прикурили бы от нее. А текст ответа был под псевдонимом отправлен
на специальный конкурс эссе, и, в общем -то, жюри никакого подвоха особо не заметило.
Ну, то есть там, окей, они не сказали, что это самая лучшая работа ever, которая там получает первый приз,
но, тем не менее, и никто и не сказал, что типа, блин, вы что, охренели, что за вообще бессвязный набор слов. И вот я вам сейчас зачитаю цитату одного из кожаных мешков из жюри, что он написал. Он сказал, что эссе хорошо сформулировано
и подкрепляет утверждение доказательствами, но идея не является оригинальной.
Ну, то есть, в целом, достаточно неплохая оценка, согласитесь. Помните, нам еще старички Гегель, Маркс и Энгелес говорили
о законе перехода количества в качество. Так вот, эта идея, что по мере наращивания размера модели у нее появляются какие-то вдруг новые свойства, она достаточно удивительная, согласитесь.
Ну, то есть, маленькие модели, они мало что могли, а модель, к которой просто увеличили количество параметров,
она внезапно научилась писать эссе вместо коротких предложений. Достаточно круто.
Давайте вот поподробнее обсудим, о чему вообще научилась GPT -2 после увеличения количества параметров. Есть специальные наборы задач на разрешение двусмысленности в тексте, которые уже очень давно используют как раз для оценки ну, типа вот разумности моделей.
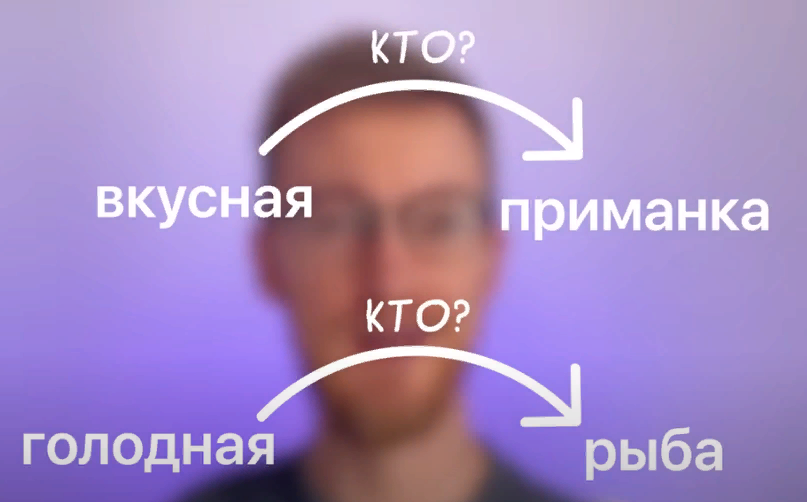
Например:
Рыба заглотила приманку. Она была вкусной. И рыба заглотила приманку. Она была голодной.
Ну, несложно понять человеку, по крайней мере, что если она была вкусной, то, наверное, приманка, раз ее заглотили.
А вот если она была голодной, то, наверное, она… это относится к рыбе, которая заглотила приманку.
Но вот если просто модель смотрит на текст, ей, если честно, не совсем это очевидно. Ну, потому что, чтобы делать такие выводы, нужно на самом деле какую -то простенькую модель мира иметь в голове, да? Потому что рыба, она, в общем -то, может быть и голодной, если она там в пруду какая -нибудь пиранья плещется, и вкусной, если она лежит на тарелке в ресторане. И вот чтобы не модель научилась отвечать на такие вопросы, это ей нужно неплохо прокачаться, согласитесь?
Так вот, люди решают такие задачки правильно примерно в 95 % случаев.
А старые модели, они вот, ну, которые с маленьким количеством параметров, они справлялись только примерно в 50%. Ну,
как в том анекдоте практически, какова вероятность встретить динозавра на улице? 50 на 50, либо встречу, либо нет.
Вот так и тут, по сути, угадывали случайно. И вы, наверное, сейчас подумали, ну, блин, говно вопрос, надо просто собрать большую базу данных таких задачек с ответами, ну, там, пару тысяч, скромить нейросетки, натренировать, и она научится правильно отвечать на эти вопросы. И исследователи раньше так и пытались сделать.
То есть они натренировали специальные нейросети на базе задачек, но у них получалось в лучшем случае там до 60 % успеха дотянуть. А вот GPT -2, ее никто специально не тренировал на это. Ее просто обучали на огромном рандомном наборе текстов разных всяких, и она сама научилась в 70 % случаев решать правильно такие задачи.
Это довольно-таки удивительно, согласитесь? Вот как раз есть тот самый переход количества в качество. И причем он
происходит совершенно нелинейно. Если вот повышать количество параметров в модели со 115 до 350 миллионов,
то какого -то сильного изменения-то мы и не видим.
А вот если еще в пару раз увеличить параметры до 700 миллионов и выше, то тут уже происходит резкий скачок, и модель внезапно научается решать задачи про голодных рыб.
Так что вот при этом надо понимать, что ей специально раньше никто не показывал эти конкретно задачи. То есть это не то, что вот она в большом объеме текста в среде-то, она просто нашла примеры таких задач и научилась.
Нет. Она просто что-то скумекала, как вообще правильно думать про мир, и начала внезапно решать эти задачи гораздо лучше специализированных своих коллег.
Краткое резюме: GPT-2 вышла в 2019 году, и она превосходила свою предшественницу и по объему тренировочных текстовых данных, и по размеру самой модели, то есть числу параметров в 10 раз.
Такой количественный рост привел к тому, что модель неожиданно самообучилась качественно новым навыкам, от сочинения длинных эссе со связанным смыслом, до решения хитрых задачек, требующих зачатка в построение картины мира. Поигравшись немного с располневшей и от этого полневшей моделью
2020: GPT-3, или Невероятный Халк
GPT-2, ребята из OpenAI решили, а что бы еще не увеличить размер модели эдак раз в 100.

В общем, вышедшая в 2020 году GPT-3 уже могла похвастаться аж в 116 раз большим количеством параметров, на этот раз в 175 миллиардов. А раскабаневшая сама модель, она уже весила невероятные 700 гигабайт. Набор данных для обучения GPT -3 тоже прокачали, хоть и не так радикально. Он вырос в 10 раз до 420 гигабайтов. Туда засунули кучу разных книг, википедию, сайты и так далее. В общем, живому человеку проглотить такой объем информации просто уже нереально.
Разве что если вы посадитесь в десяток Анатолиев Вассерманов, чтобы они по 50 лет каждый нон-стоп, просто без перерывов читали разную информацию из интернета. Сразу бросается в глаза интересный нюанс. В отличие от своей предшественницы GPT -2, новая модель GPT -3, она даже больше по размеру, 700 гигабайт занимает, чем весь текст, на котором ее тренировали, 420 гигабайт. Получается как будто бы парадокс.
То есть модель прочитала текст на 400 гигабайт, и при этом как-то извлекла оттуда информации аж на 700 гигабайт.
Больше, чем как будто бы там содержалось внутри. И вот такое обобщение, или можно сказать осмысление моделью,
оно позволяет ей еще лучше прежнего делать экстраполяцию. То есть решать задачки на основании текстов, которые практически очень редко или вообще не встречались в тренировочном наборе данных. И теперь уже точно не нужно учить GPT-3 каким -то образом специально решать узкие задачи.
Нет, ей можно просто сказать, чего вам нужно, пару примеров ей кинуть, и уже GPT -3 вот разберется, что вы от нее хотите
получить в итоге. И тут в очередной раз оказалось, что универсальный Хаук в виде модели GPT -3, он внезапно с легкостью кладет на обе лопатки многие специализированные модели, которые были заточены на вот ровно одну узкую задачу.
Ну вот, например, перевод текстов с французского или немецкого на английский давался GPT -3 гораздо лучше, чем многим специализированным моделям, что на самом деле довольно удивительно. Ну то есть я напоминаю, что вот эти
вот все нейросетки, они заточены ровно на одну задачу, предсказывать одно следующее слово, которое идет за текущим текстом.
А вот переводить конкретно никто GPT-3 не учил, но она как -то сама научилась этим возможностям.
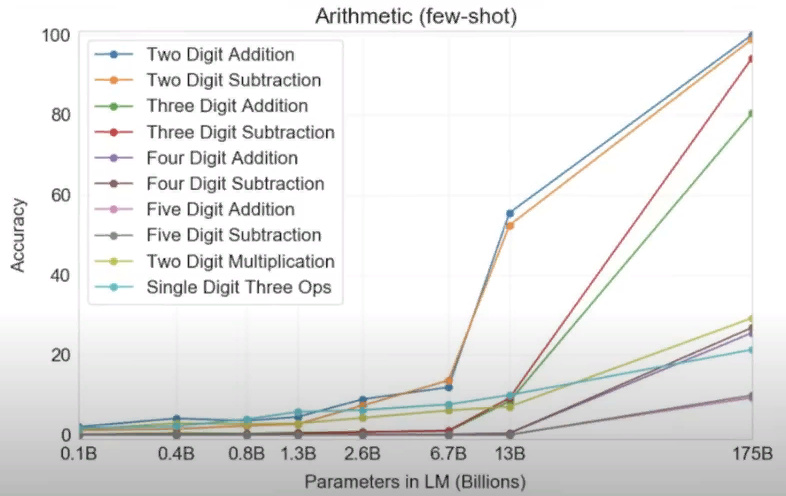
Откуда у нее эти способности к переводу? Сразу так и не разберешь. Но это еще цветочки. Еще более удивительно, что GPT -3 смогла сама научить себя математике. На экране вы видите график, где показана точность ответов нейросетей с разным количеством параметров на задачки, связанные со сложением или вычитанием, а также с умножением чисел вплоть до пятизначных. И, как видите, при переходе от модели с 10 миллиардами параметров к 100 миллиардам нейросети внезапно и резко начинают уметь в математику.
Еще раз вдумайтесь, языковую модель просто учили продолжать тексты словами, а она сама каким -то образом смогла сообразить, что если ей на вход пишут 378 плюс 789, то на это надо отвечать именно как 1167, а не каким -то другим рандомным набором чисел.
Магия, согласитесь, это настоящая магия. Хотя многие говорят, что на самом деле нейросетка просто в тренировочном наборе данных запомнила все возможные примеры и ответы на них. Так что вот дебаты еще идут, это попугайство или настоящая магия.
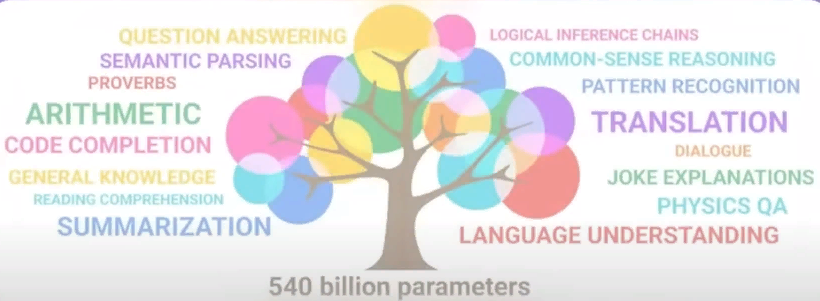
Но тем не менее факт остается фактом, что при увеличении размера параметров модели в них внезапно начинают прорастать
какие -то новые специальные умения, которые никто специально не закладывал. И вот на экране сейчас прям можно увидеть
анимацию в виде дерева, как опять же по мере роста параметров модели в ней как бы прорастают новые настоящие способности.
И кстати, вот задачу проголодных рыб, которую мы до этого обсуждали, и которой мучили GPT-2, GPT -3 уже смогла решать на уровне 90 % точности. Ну то есть прям как человек.
И это на самом деле заставляет задуматься, а что будет, если еще раз в 100 увеличить количество параметров у модели? Каким новым способностям она тогда научится?
Давайте здесь сделаем небольшое отступление и поговорим о промтах.
Промпты, или как правильно уламывать модель
Промты — это как раз текстовые запросы в модель, о которой она должна продолжить. И вот от того, как вы сформулируете этот самый промт, будет очень сильно зависеть качество ответа.
Например, если вы нейросеть просите решить какую-нибудь простенькую математическую задачку на уровне 5 или 6 класса, то она нередко ошибается и пишет неправильное число. Но есть волшебное слово, если которое дописать в конец вашего промта, то модель внезапно начинает гораздо лучше ее решать.
И это не «пожалуйста», а как раз таки слова «Let’s think step by step», то есть «давай подумаем шаг за шагом». И вот если это подсказать модели, то она начинает прям как школьник решать по шагам задачу и приходит к правильному ответу.
Довольно таки удивительно, согласитесь. То есть вот можно ее реально как бы учить правильно думать, как можно сказать.
И при этом в компаниях сейчас даже нанимают специальные должности промт -инженеров, так называемых, которые как раз таки умеют с моделью говорить на одном с ней языке.
Я прямо вангую, что уже скоро появится куча инфо-цыганских курсов, типа там «за 6 недель научись правильному промт-инжинирингу и вкатись на перспективную специальность за 300 тысяч рублей в месяц».
Ну, на самом деле это логично, потому что такие нейросети, как вот ChatGPT, они становятся неотъемлемыми инструментами для людей. И вполне вероятно, что во многих специальностях как раз таки нужно будет уметь правильно общаться с моделью, чтобы добиваться результатов в своей профессии.
Краткое резюме: GPT -3 образца 2020 года была в 100 раз больше своей предшественницы по количеству параметров и в 10 раз по объему тренировочных данных. И снова рост количества привел к внезапному скачку в
качестве. Модель научилась переводу с других языков, арифметике, базовому программированию, пошаговым рассуждениям и многому другому.
Январь 2022: InstructGPT
Воспитание строптивой нейросети по себе не означает, что они будут отвечать на запросы именно так, как хочет пользователь. Ну, потому что люди, когда что-то просят друг у друга, они очень часто имеют в виду множество таких вот скрытых еще дополнительных уточнений, которые можно и не проговаривать, потому что любым нормальным людям типа и так понятно.
Ну вот, например, представьте, что Маша просит своего мужа «Вась, сходи выбрось мусор». И ей, скорее всего, не придет в голову добавить к этой просьбе «Только, пожалуйста, не из окна». Ну, потому что Вася, как любой нормальный человек, понимает, что речь идет про то, что нужно взять мусор, спуститься вниз, дойти до мусорного бака и выбросить уже туда. А вот языковые модели, если честно, они не очень похожи на людей.
Поэтому им в запросах очень часто приходится прям вот разжевывать и прям какие-то вещи, которые очевидны людям, дословно расписывать. Слова «давай подумаем шаг за шагом» из предыдущего примера, они как раз вот и относятся к такому разжевыванию. Ну, потому что среднестатистические взрослые, я думаю, они бы догадались сами, что если речь идет про математическую задачку, то нужно ее решать по действиям, по шагам.
А модели приходится объяснять. И вот было бы здорово, если бы модели, они как -нибудь сами научились бы,
во-первых, из коротких инструкций, сами для себя придумывать более развернутые инструкции, исходя из того, что они ожидают, человек бы хотел увидеть. Ну и во-вторых, они бы учились исполнять эти инструкции таким образом, чтобы вот опять же предсказывать ожидания людей.
Отчасти отсутствие способностей моделей предсказывать желания людей, оно связано с тем, что вот GPT-3, ну, это просто языковая модель, которая натренирована на огромном количестве текстов из интернета. Ну и сами знаете, в интернете много чего написано, как и на заборе, но не всегда это полезная и хорошая информация.
А вот люди хотели бы, чтобы искусственный интеллект, рожденный таким образом, он вот как -то сам научился подтаскивать точные и хорошие ответы, но при этом был не токсичным и никого не оскорблял. Ну иначе такую языковую нейросетку
быстро закэнселят, с этим нынче дела обстоят достаточно проворно, а создателям ее просто предъявят гигантские иски в суде
за то, что модель ее оскорбляет кожаных мешков и вообще зигует напропалую.
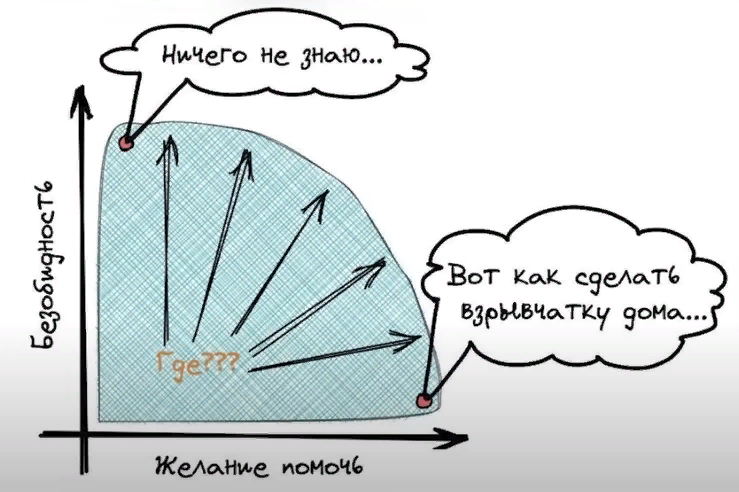
И вот когда исследователи думали над этой проблемой, они довольно быстро выяснили, что такие свойства модели, как точность и полезность и безобидность или нетоксичность, они как бы находятся в противофазе друг к другу, ну или противоречат друг другу.
Ведь точная модель должна честно отвечать на вопрос «Окей, Google, а как сделать коктейль молотова без регистрации и смс?» А наоборот, вот максимально безобидная модель в пределе, она на любой вопрос будет отвечать «Извините, я не знаю, ведь мой ответ может в интернете кого -то оскорбить».
Получается, что создание искусственного интеллекта, выравненного по ценностям с человеком, это такая сложная задача по поиску баланса и правильного ответа, там просто по сути нет. И вокруг всей этой проблемы выравнивания искусственного интеллекта или на английском это называется AI alignment, есть огромное количество этических вопросов. Мы их все сейчас разбирать не будем. Это тема для одного из следующих видео.
Но скажу здесь просто, что одна из загвоздок в том, что вот таких разных этических ситуаций, этических дилемм, их огромное количество. И правильного ответа для большинства из них просто нет. Ну, сами подумайте, люди за 10 тысяч историй своей, более-менее записанной, они между собой даже не могут договориться, что есть правильно, что плохо, в какого бога верить и так далее.
Что уж говорить о том, чтобы они смогли вот для робота какие-то понятные правила расписать, и чтобы все люди согласились, что да, вот именно так -то и нужно себя роботу вести. Нет, к сожалению, это утопия.
И даже вот три правила робототехники от Айзека Азимова, они не такие уж и очевидные, если честно, если их применять к нейросетям. И в итоге исследователи не придумали ничего лучше, кроме как дать нейросетке очень много обратной связи.
Если подумать, то человеческие детеныши, они как раз таким образом в морали и обучаются. Они с самого детства творят очень много всяких разных вещей и внимательно смотрят при этом на взрослых. И, короче, инстракт GPT, который мы наконец дошли, и также известная как GPT -3.5, это и есть как раз нейросетевая модель GPT-3, которую дообучили на фидбэке от живого человека.
То есть она была настроена на то, чтобы максимизировать оценку от такого вот мясного жюри, так сказать. Буквально куча людей сидели, и они оценивали кучу ответов нейросетки на тему того, что вот они были хорошие, похожие на ожидания этих людей или нет. И нейросеть, она выходит, дообучалась на еще одну дополнительную задачу, а как мне подкорректировать свой ответ таким образом, чтобы он понравился наибольшему количеству людей.
Причем, с точки зрения общего процесса обучения модели, этот финальный этап до обучения на обратной связи от живых людей, он занимает, ну, не больше 1%. Но именно этот финальный штрих стал тем самым секретным соусом, который сделал GPT -3 .5, все последующие модели из семейства GPT, такими потрясающими. То есть, получается, GPT -3 до этого уже обладала всеми необходимыми навыками. Она помнила огромное количество текстов, знала иностранные языки и так далее, умела подражать стилям разных авторов. Но именно обратная связь от людей, она сделала эту модель настолько классной, что люди стали просто дичайше кайфовать от ее ответов.
То есть, получается, GPT -3 .5 или InstructGPT, это, так сказать, первая нейросетевая модель, которая была воспитана
обществом в действительности. Краткое резюме. GPT -3 .5 появилась в начале 2022 года. И главной ее фишкой стала
дополнительная дообучение на основе обратной связи от живых людей. Получается, что эта модель формально вроде как больше и умнее не стала, но зато научилась подгонять свои ответы таким образом, чтобы люди от них дичайше кайфовали.
Ноябрь 2022: ChatGPT – хайпуют все!
Ну и, наконец, мы добрались до чат GPT. Она вышла в ноябре 2022 года.
Через 10 примерно месяцев после своей предшественницы InstructGPT или GPT -3.5 и мгновенно прогремела на весь мир. Кажется, последние несколько месяцев даже бабушки на лавочке перед подъездом они вот обсуждают между собой, а что там нового сказала эта ваша чат GPT, чему она научилась и кого она скоро оставит без работы. При этом, с технической точки зрения, кажется, у чат GPT особо сильных отличий от того же самого InstructGPT вроде как нету.
То есть, судя по всему, она не стала там сильно больше или умнее или еще что -то. Хотя мы можем здесь только догадываться, потому что OpenAI, они не выложили вот прям конкретного какого -то научного исследования, научные статьи на эту тему.
Но, тем не менее, по костным признакам мы можем догадаться, что реально там нет каких -то кардинальных отличий
в размере параметров и так далее. Ну окей, ладно, про некоторые вещи мы знаем, что ее там немножко дотренировали на дополнительном наборе данных, потому что сам вот этот диалоговый формат, в который переключилась чат GPT, он все-таки определенные дополнительные условия вносит.
Ну, например, вот если тебе что -то непонятно, можно получается у пользователя переспросить. А предыдущие модели, они этого не знали. Но, опять же, это не какое -то кардинальное техническое изменение. Это небольшие доработки всего лишь. И отсюда возникает вопрос, как так? Почему мы не слышали никакого хайпа про GPT 3 .5 еще в начале 2022 года?
Ведь даже сам Сэм Олтман, это исполнительный директор OpenAI, он писал в Твиттере, что типа мы сами удивились, что чат GPT трек прогремела сразу после выхода. Ведь уже 10 месяцев до этого в открытом доступе лежала похожая по способностям языковая модель, а никто особо даже и не чесался. И это удивительно, но, похоже, главный секрет успеха чат GPT – это всего лишь удобный интерфейс.
Ну, потому что InStrike GPT или GPT 3 .5, к ней можно было обращаться только через специальный API -интерфейс. То есть сделать это могли только нерды и айтишники, которые немножко умеют в программировании. А вот обычные люди, у них появился доступ только с чат GPT, потому что к ней прикрутили совершенно привычный,
удобный интерфейс диалогового окна, как в любом привычном мессенджере, и открыли публичный доступ вообще для всех.
И люди ринулись разговаривать с нейросетью, скринить самые смешные ответы ее, и постить везде в соцсетях, и просто начался взрыв хайпа. Как и в любом технологическом стартапе, здесь оказалась важна не только сама технология, но и обертка, в которую она была завернута. Ну то есть у вас может быть самая умная языковая модель, самая классная нейросетевая, искусственно -интеллектуальная штука, но если к ней не прилагается удобный и понятный всем интерфейс, то возможно всем будет просто тупо наплевать.
И чат GPT в этом смысле настоящую революцию устроил. То есть он действительно сделал такой вот классный, удобный, привычный диалоговый интерфейс, в котором дружелюбный робот слово за словом печатает вам ответ. И неудивительно, что чат GPT установил абсолютный рекорд по популярности.
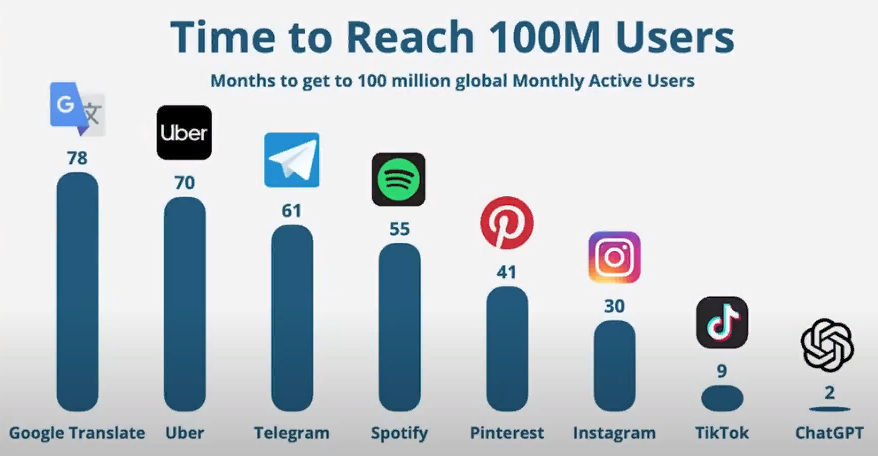
То есть отметку в 1 миллион юзеров он достиг в первые 5 дней после релиза, а за 100 миллионов юзеров он перевалил всего за 2 месяца. Это просто удивительные до этого невиданные скорости привлечения новых пользователей.
Ну а там, где есть рекордно быстрый приток сотен миллионов пользователей, конечно же быстро появился и приток огромных денег. Microsoft заявили, что они готовы 10 миллиардов баксов инвестировать в OpenAI, чтобы совместно с ними делать всякие разные штуки. Google забил тревогу, сел думать, как им спасать свой поисковый бизнес от нашествия нейросетей.
Китайцы сразу тоже объявили, что они планируют что-то интересное там делать. В общем, все начали дико хайповать,
дико вкачивать туда деньги. Но, если честно, это совсем другая история, за которой вы прямо сейчас можете, так сказать,
в прямом эфире наблюдать.
Краткое резюме: Модель чат GPT вышла в ноябре 2022 года. И с технической точки зрения там не было никаких особых нововведений. Но зато у нее был удобный интерфейс взаимодействия и открытый публичный доступ, что немедленно породило огромную волну хайпа. А в нынешнем мире это главнее всего.